






Agentic AI
How to Use Hermes Agent with Trinity Large Thinking
3 min read • Apr 3, 2026

News
Trinity-Large-Thinking: Scaling an Open Source Frontier Agent
5 min read • Apr 1, 2026

News
Trinity Large
8 min read • Jan 27, 2026

Research
Distilling Kimi Delta Attention into AFM-4.5B (and the Tool We Used to Do It)
9 min read • Dec 15, 2025

News
The Trinity Manifesto
10 min read • Dec 1, 2025

News
Mergekit Returns To Its Roots
3 min read • Oct 31, 2025
Open-Source Toolkits
IBM Research Uses Arcee MergeKit in Granite 4.0 Model Development
2 min read • Oct 6, 2025
Research
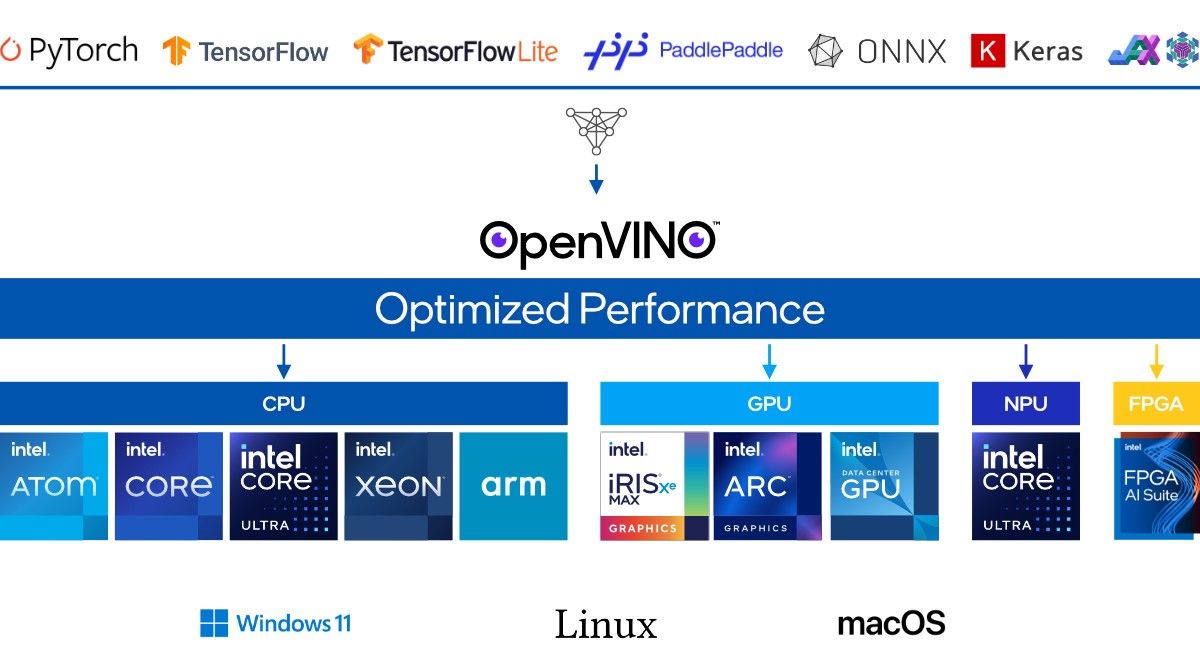
Optimizing Arcee Foundation Models on Intel CPUs
6 min read • Sep 30, 2025

Company
Arcee AI Secures Strategic Investment to Accelerate Enterprise-Grade AI Platform Built on AFM Foundation Models
5 min read • Jul 30, 2025