.webp)
Company
•
April 14, 2026
Introducing the Trinity Builders Program
A community credit grant for developers, researchers, and open source builders working with Trinity models. Apply for free inference access on the Arcee API.
Built for performance, compliance, and affordability.
Today marks a pivotal moment for Arcee AI and our customers: the launch of AFM-4.5B, the first Arcee Foundation Model. AFM-4.5B is the result of a deliberate, ambitious effort to deliver enterprise-grade AI that meets the real needs of today's organizations: performance, compliance, and affordability—at a scale and quality not previously available.
For a quick taste, you can test AFM-4.5B in our playground and on Together.ai.
Our journey began in response to a pattern we saw across countless customer deployments. Over the years, we've helped organizations push AI further, driving better performance and lower costs through precision tuning and targeted post-training. But as AI adoption grew, we saw a set of inescapable pain points emerge.
Edge-optimized models weren’t simply reliable enough for demanding tasks. Customers needed a model that could run on modest hardware, yet still deliver top-tier accuracy and robustness.
The most advanced models from major Chinese AI labs (Deepseek, Qwen, GLM, MiniCPM) offered impressive results, but rarely satisfied Western compliance standards, disqualifying them for regulated industries.
Models from Meta (Llama) and Mistral, while solid, were quickly becoming outdated in relevance. The 3–10B parameter space was primarily served by models a year old or older, outpaced by newer research, data pipelines, and post-training strategies.
Customers faced a hard choice: compromise on performance, compliance, or future flexibility. We knew there had to be a better way. The answer wasn’t a patchwork of tweaks or incremental improvements. We committed to a bold course: design and train a new model, from the ground up, for the world our customers actually operate in.
Training a foundation model of this scale is never simple. We took on the challenge not just to build a better model, but to prove that focus, rigorous data practices, and deep expertise could deliver a step-change in real-world utility.

We knew that in order to build the strongest models possible, we needed the best possible training data. To achieve this, we partnered with DatologyAI, the leading experts in data curation, to assemble 6.58 trillion tokens of the most relevant, highest-quality data possible.
Data curation for foundation models is hard. It's a frontier research problem—it's a comparatively new field, experiments are costly to run at scale, and small-scale results often aren't predictive of large-scale outcomes. It's also a frontier engineering problem—there's no established playbook for implementing a curation pipeline that can scale up to the trillions of tokens that needed to train competitive foundation models. We knew it just wouldn't make sense to try to tackle this ourselves. This is why we chose to partner with DatologyAI.
DatologyAI's curation pipeline integrates a suite of proprietary algorithms—model-based quality filtering, embedding-based curation, target distribution-matching, source mixing, and synthetic data—and customizes them to generate a strong general-purpose dataset that also targets the capabilities we wanted our model to have. The results showed early: by 2 trillion tokens, AFM-4.5B was already outperforming competing models trained on dramatically larger, but noisier datasets.
We utilized Amazon SageMaker Hyperpod and orchestrated training across 512 Nvidia H200 GPUs. This cloud infrastructure enabled us to experiment rapidly with various architectural variants, hyperparameter sweeps, and targeted interventions.
AFM-4.5B’s clean foundation made it a prime candidate for our multi-stage post-training pipeline—built to adapt the model to enterprise demands through advanced fine-tuning, distillation, merging, and alignment techniques.
AFM-4.5B is purpose-built for organizations that won't settle for compromises.
Optimized for high throughput on CPUs, AFM-4.5B delivers GPU-tier results with efficient resource usage—ideal for both cloud and on-premise scenarios.
From enterprise servers to mobile devices and IoT modules, AFM-4.5B scales effortlessly, supporting AI where you need it. On an Amazon EC2 c8g.8xlarge instance (Graviton4, 32 vCPUs), an 8-bit version of AFM-4.5 running on llama.cpp can deliver well over 100 tokens per second at batch size 4. A 4-bit version delivers over 200 tokens per second. This combination of high-quality generation and high CPU performance opens up cloud and edge use cases that were impossible until now.
We designed AFM-4.5B with real-world use cases in mind and have refined it to handle a broad spectrum of workloads with precision and reliability.
We built AFM-4.5B to be more than just a foundation model; it's a launchpad for fast, reliable deployment in the real world.
Drop-in kits enable AFM-4.5B to power tool use, retrieval-augmented generation, and agentic reasoning—securely and on your infrastructure.
Fine-tune the model to your vertical in hours, not months. Our pipelines and documentation help you take full control without unnecessary overhead.
At the heart of AFM-4.5B’s real-world performance is its post-training stack—a layered strategy that surfaces and sharpens capabilities without sacrificing generality or introducing brittleness.
It begins with midtraining, where we infused the model with high-leverage datasets (math, code, complex reasoning) and carefully selected samples from DatologyAI’s corpus. This step gave the model strong early instincts for precision and clarity. From there, we performed checkpoint merging, consolidating, and enhancing intermediate models into a cohesive base. We extended context length using YaRN, a rotary scaling method that retains performance at scale, and refined this long-context foundation through advanced merging using MergeKit, our open-source tool. MergeKit allowed precise control over the model’s composition—layer-wise weighting, residual scaling, and targeted integrations—all of which contributed to consistency across varied tasks.
Next, we conducted supervised fine-tuning, focusing on instruction clarity, diversity, and alignment. Here, the model learned to adapt to a wide range of prompts—from legal analysis to creative writing—while avoiding the overfitting that weakens many instruction-tuned models.
Finally, we applied reinforcement learning using verifiable reward signals, helping the model prefer factual, high-utility responses. Post-RL merges smoothed out inconsistencies, and we followed with KTO, an alignment method where the model learns directly from trusted reference behavior.
This comprehensive stack ensures that AFM-4.5B not only performs well out of the box but remains reliable, steerable, and robust, ready for the highest-stakes enterprise environments.
Here are benchmarks for AFM-4.5B-Base (pre-distillation) and AFM-4.5B-Preview.
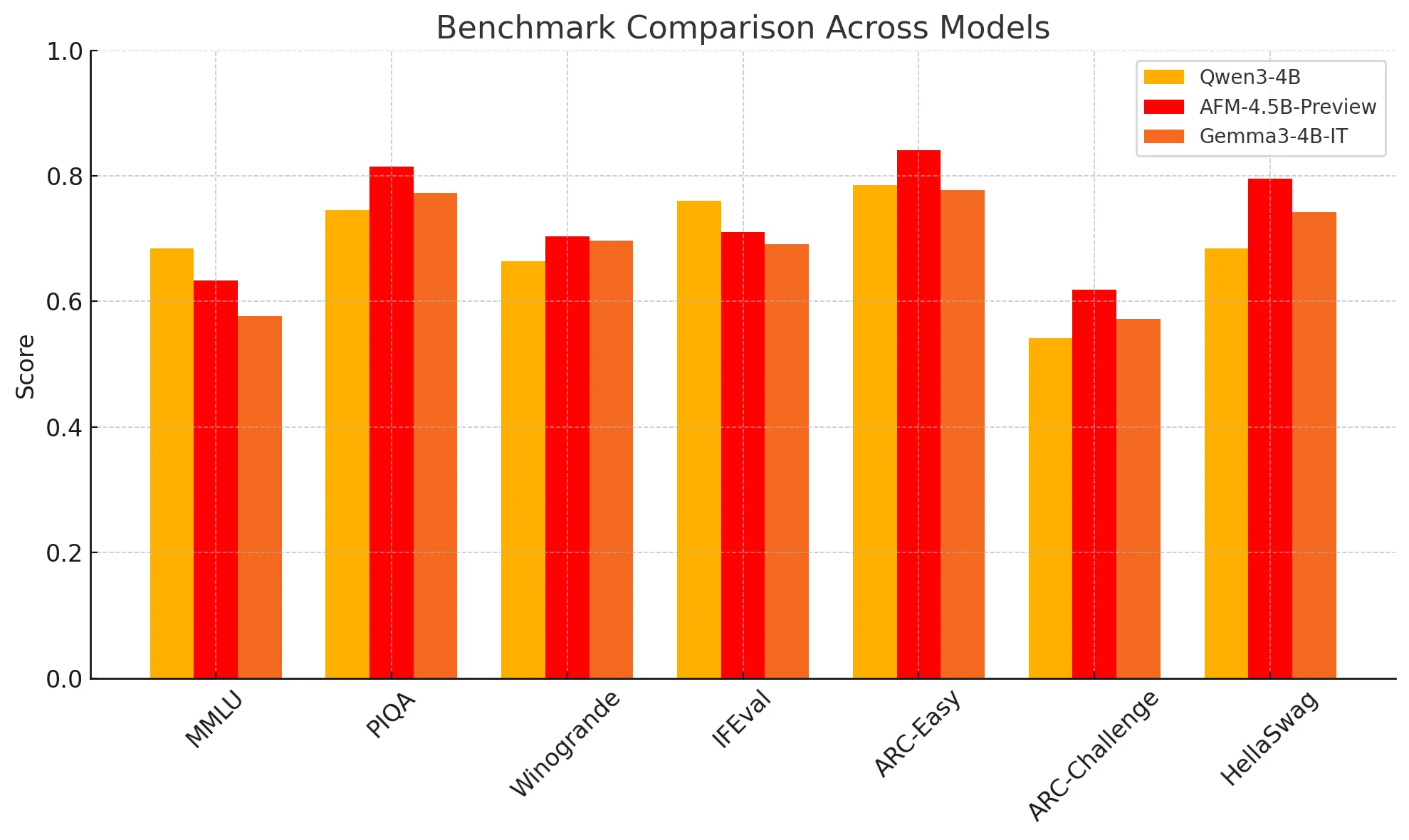
AFM-4.5B is our most advanced model yet—but just the beginning. We're developing smaller variants for ultra-constrained edge devices, and scaling up for reasoning-intensive workloads. Whatever your requirements, we’re committed to delivering models that are powerful, transparent, and enterprise-ready.
As we move toward full release, here’s what you should know:
We believe in transparency, openness, and community-driven development, and these releases reflect our commitment to making high-quality AI more accessible.
Here’s how to get involved:
With AFM-4.5B, we're not just launching a model—we're launching a new era. Every layer of this system, from training data to post-training alignment, was built with one goal: to meet your needs with no compromises. Whether your priorities are cost, compliance, or performance, we’ve built AFM-4.5B to exceed expectations—on your terms.
Ready to see what AFM-4.5B can do for your enterprise? Let’s build this chapter together. Reach out for a demo or contact sales@arcee.ai—we’d love to collaborate with you.
Building AFM was a company-wide effort, and we’d like to thank the extended Arcee AI team for their contribution: Fernando Fernandes, Varun Singh, Charles Goddard, Lucas Atkins, Mark McQuade, Maziyar Panahi, Conner Stewart, Colin Kealty, Raghav Ravishankar, Lucas Krauss, Anneketh Vij, Pranav Veldurthi, Abhishek Thakur, Julien Simon, Scott Zembsch, Benjamin Langer, Aleksiej Cecocho and Maitri Patel.
.webp)
.webp)