
Agentic AI
•
April 3, 2026
How to Use Hermes Agent with Trinity Large Thinking
Learn how to set up Hermes Agent powered by Trinity-Large-Thinking. This guide covers installation, tool configuration, and launching your AI assistant.
.webp)
Discover how knowledge distillation makes AI models faster, more efficient, and cost-effective without sacrificing performance. Learn how Arcee AI leverages this technique to optimize models like Virtuoso Lite and Virtuoso-Medium-v2, delivering powerful AI solutions with lower computational demands. Explore the benefits, use cases, and how your organization can implement knowledge distillation to scale AI performance while reducing costs.
What if your AI models could work faster, consume fewer resources, and still deliver top-tier performance? Companies like Arcee AI are proving this is possible through knowledge distillation.
A prime example is Virtuoso Lite, Arcee AI’s distilled version of DeepSeek-V3, which is now the best sub-14B open model available. Alongside it, Virtuoso-Medium-v2 pushes the boundaries of efficiency in 32B small language models, demonstrating how distillation can scale AI performance while significantly reducing computational demands. These models showcase how advanced distillation techniques make cutting-edge AI more accessible without sacrificing quality.
AI adoption can get very expensive, so knowledge distillation offers a practical solution. Let’s explore how this technique works, why it’s a game-changer, and how your organization can benefit from it.
Modern AI models are capable of generating human-like text, analyzing vast datasets, and powering personalized recommendations. However, these capabilities come with a hefty tradeoff: size.
Many state-of-the-art machine learning models, like GPT-4 or OpenAI’s O3, are incredibly resource-intensive and require huge amounts of computational energy, power, and infrastructure to function effectively.
For businesses, this poses significant barriers:
While complex models like O3 demonstrate impressive capabilities, their cost makes them impractical for all but the most well-funded enterprises. These challenges paved the way for knowledge distillation, which makes AI more accessible, scalable, and sustainable.
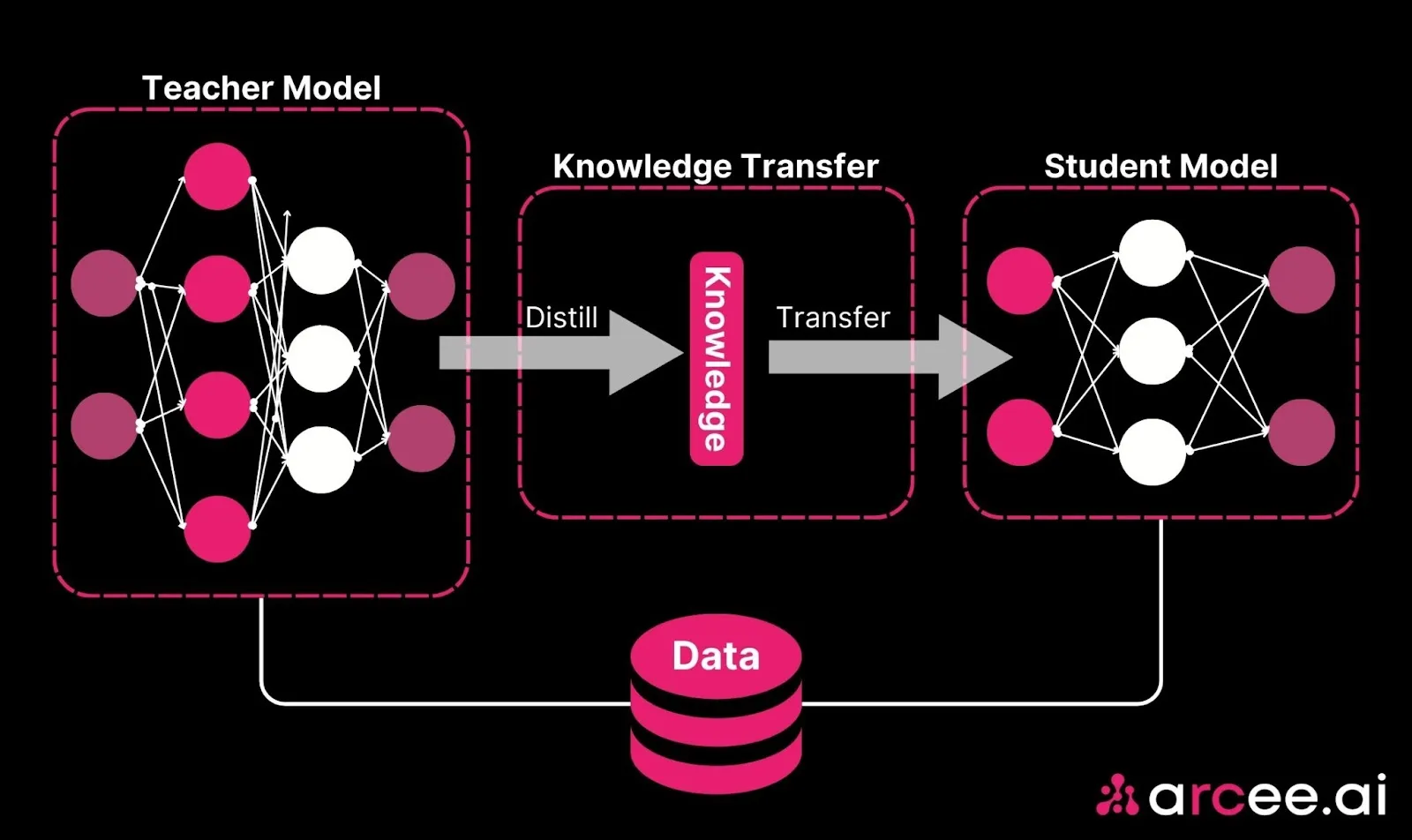
Knowledge distillation or model distillation is a process that compresses large, complex deep learning models into smaller, more efficient versions while retaining most of their performance capabilities. The process involves a "teacher" model—a larger, resource-intensive AI system—training a smaller, lightweight "student" model by transferring its learned knowledge.
In some cases, online distillation is employed, where the teacher and student models train simultaneously. This dynamic approach allows real-time feedback and adaptation, making the process more efficient for rapidly evolving datasets.
Think of it this way: imagine a seasoned CEO (the teacher) condensing years of leadership experience, strategies, and insights into a practical guide for a new manager (the student). The student then applies this distilled knowledge to achieve similar results but with fewer tools and resources.
This technique ensures that the smaller model retains the critical capabilities of the original while reducing computational demands.
Now that we’ve explored what knowledge distillation is, let’s talk about the benefits this technique offers for AI models and why it’s becoming a go-to solution for businesses looking to optimize their AI systems.
Knowledge distillation enables the creation of smaller, faster models that retain the performance of large language models by focusing on critical information and eliminating redundancies. These student models are more lightweight and efficient, leading to faster processing speeds and reduced hardware requirements without sacrificing precision.
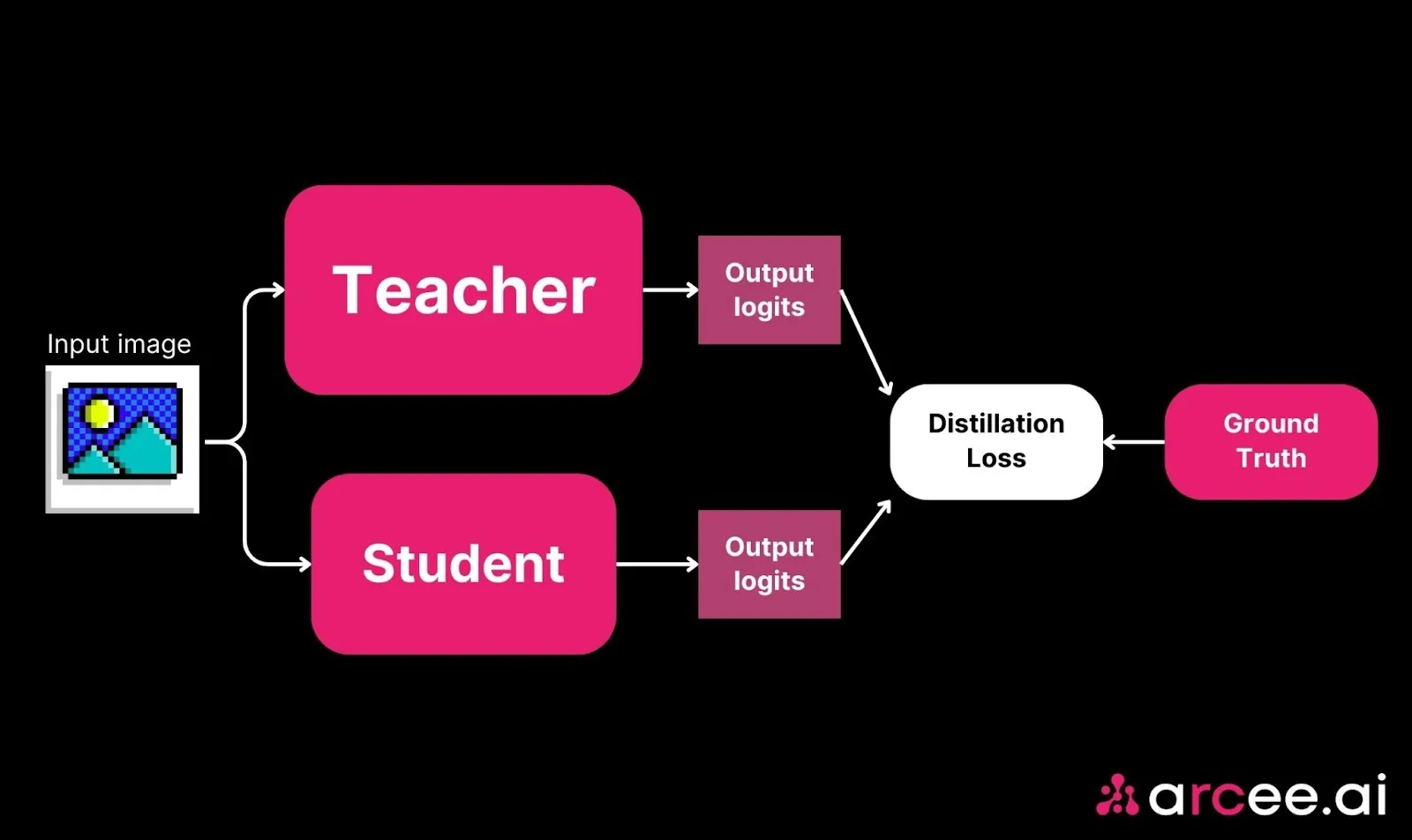
For instance, research has shown that certain distillation methods can reduce computational costs by up to 25% with minimal impact on classification performance. This efficiency is particularly valuable for computer vision tasks such as object detection and image recognition, where real-time processing and reduced resource requirements are critical.
The student model doesn't simply replicate outputs; it learns the deeper reasoning of the teacher model. By using soft targets, which represent the probability distribution of various possible outcomes, the student model gains a nuanced understanding of the data. This approach allows the student to generalize effectively, performing well even on unseen tasks or datasets, thereby maintaining the critical decision-making capabilities of the original model.
By focusing on knowledge transfer and continual learning, the student network gains a deeper understanding of the teacher model’s reasoning process.
Smaller models inherently require less energy and fewer resources to train and operate. By employing knowledge distillation, businesses can significantly reduce infrastructure costs and ongoing operational expenses. This reduction makes AI more accessible to organizations that may have been previously deterred by high costs.
For example, a study demonstrated that using knowledge distillation techniques led to a 21% improvement in performance for certain tasks.
By addressing these challenges, knowledge distillation reshapes how companies approach AI.
Let’s break down the key components of knowledge distillation, including the dynamic teacher-student relationship, the use of soft targets, and the training mechanisms that allow the student model to retain the capabilities of its teacher.
As mentioned earlier, the teacher model is a large, resource-heavy AI system extensively trained on a dataset. Its job is to guide a smaller, more efficient student model, transferring its learned knowledge to replicate its capabilities.
This process allows the student model to perform similarly to the teacher while requiring significantly less computational power, making it ideal for deployment in environments with limited resources.
One of the critical components of knowledge distillation is the use of soft targets. Instead of simply providing the correct answers, the teacher model outputs probabilities for all possible outcomes, giving the student model deeper insights into its reasoning process. These probabilities help the student generalize better to new tasks, ensuring it learns the teacher's nuanced decision-making process.
Learn more about how distillation leverages soft targets in our guide to DistillKit.
The student model is trained using a combination of two types of feedback:
Together, these feedback mechanisms allow the student model to match the teacher’s performance on critical tasks while requiring a fraction of the resources.
Amazon's Alexa employs knowledge distillation to improve its speech recognition capabilities while remaining efficient for consumer devices. Using a teacher-student training framework, Amazon’s team used over 1 million hours of unlabeled speech data to generate soft targets for training. This approach enabled a more efficient acoustic model that enhanced Alexa’s ability to understand and process speech.

The use of knowledge distillation allowed Amazon to deliver accurate speech recognition on devices with limited computational resources. This example highlights how knowledge distillation can optimize AI systems and make them practical and effective for widespread use, even on devices with hardware constraints.

Arcee AI’s Virtuoso-Lite (10B) and Virtuoso-Medium-v2 (32B) are distilled from DeepSeek-V3, delivering smaller, faster, and cost-effective AI models without sacrificing performance. By applying advanced distillation techniques, these models achieve faster inference and lower computational costs. This makes them ideal for enterprise applications and real-time decision-making.
If your organization is seeking faster, cost-effective, and scalable AI solutions, knowledge distillation could a key element of your model training process. By reducing the size of AI models while preserving their capabilities, this technique offers an ideal path for businesses looking to integrate AI into their workflows without breaking the bank or overloading their infrastructure.
At Arcee AI, knowledge distillation isn’t just a feature—it’s one of the foundational steps of our world-class model training pipeline. All of our AI models are trained using this technique, ensuring they are lightweight, efficient, and tailored to real-world business needs. Our specialized models are ready to deliver, whether you’re looking to automate workflows, enhance customer support, or power decision-making processes.
To determine if knowledge distillation is the right fit for your organization, consider these guiding questions to align your AI strategy with your business needs:
Could they improve customer support, enhance decision-making, or streamline operations? Distilled multilingual models are particularly useful for natural language processing tasks like chatbots, sentiment analysis, and automated translation, where efficiency is critical.
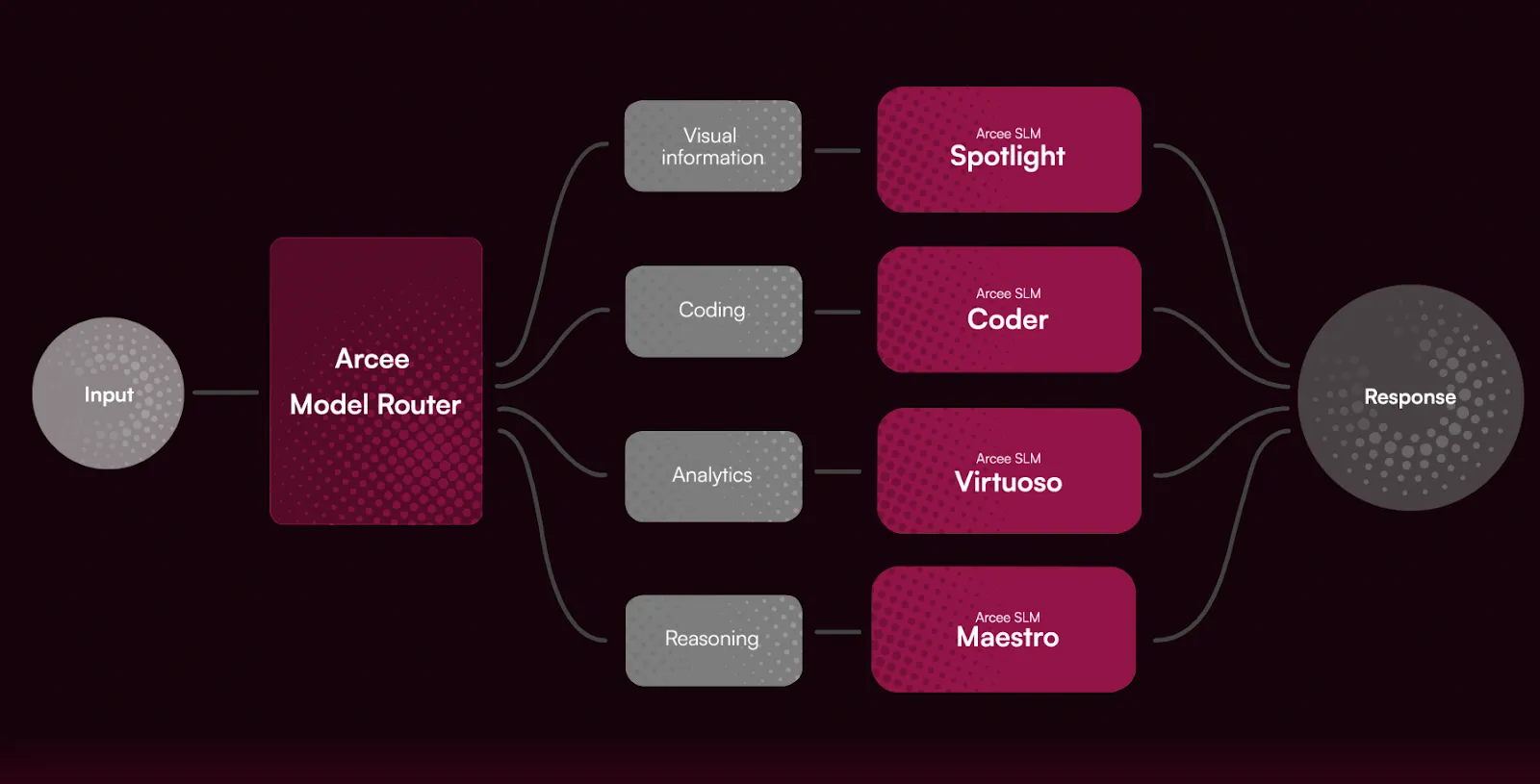
Arcee's AI agent system, powered by small language models trained through knowledge distillation, is designed to tackle your unique business challenges. These models combine efficiency and accuracy, making them particularly effective for applications where resource constraints are a concern.
Want to learn more about how AI agents can help your business? Check out our Complete Guide to AI Agents for Businesses.
As pioneers in knowledge distillation, Arcee has fine-tuned this technique to create models that outperform traditional large-scale models in usability, speed, and cost-efficiency. By using Arcee’s solutions, your organization can skip the heavy lifting of training and deploying oversized models and instead focus on leveraging AI optimized for your use case.
Ready to explore how knowledge distillation and AI agents can elevate your business? Learn more about AI use cases or contact Arcee today to transform your operations with advanced AI solutions.
Knowledge distillation focuses on transferring knowledge from a larger teacher model to a smaller student model while retaining performance. Model compression, on the other hand, uses techniques like pruning or quantization to reduce a model's size without explicitly leveraging a teacher-student framework.
Absolutely. Knowledge distillation creates smaller, cost-efficient models that require fewer resources, making advanced AI accessible to businesses with limited budgets or infrastructure.
Google used knowledge distillation to create smaller BERT models and enable faster processing on mobile devices. Arcee AI’s Virtuoso-Lite and Virtuoso-Medium-v2, distilled from DeepSeek-V3, deliver high-performance small models, reduce costs, and maintain strong AI capabilities.
Knowledge distillation offers a transformative approach for businesses seeking efficient, cost-effective, and scalable solutions. With this technique, organizations can benefit from faster models that maintain high performance, reduced operational costs, and AI systems that are easier to deploy across diverse environments.
For innovative leaders, this is an opportunity to stay ahead of the curve by adopting AI systems designed for real-world success. With Arcee’s specialized models, trained using knowledge distillation, you can unlock the full potential of AI without the heavy resource demands of traditional large-scale models.
Discover how Arcee AI can help implement optimized AI solutions tailored for your business—book a demo today.

