
Partnerships
•
June 9, 2026
Why we made Hugging Face the home for everything we build
Arcee partners with Hugging Face to make the Hub the exclusive home for all models, datasets, and agent traces.
.webp)
Thanks to a chatbot interface powered by open-source small language models and real-time data analytics, store associates can interact naturally through voice or text.
We ran a live stream on June 10 from the floor of Cisco Live. You can watch it on YouTube.
The retail landscape is rapidly evolving, with AI-driven solutions reshaping how stores operate and engage with customers. Today's consumers expect personalized, efficient service, while staff need immediate access to accurate information on customer traffic, inventory, sales, and other key metrics. Meeting these demands requires powerful edge computing solutions that can process and deliver insights in real-time.
Powered by Intel Xeon 6 CPUs running in a Cisco UCS server, the Edge IQ Retail Assistant exemplifies this potential. This technical demonstrator will be featured in the Intel Showcase (#3035) at Cisco Live 2025, taking place in San Diego, CA, from June 8 to 12, 2025. Attendees will get a firsthand experience of how generative AI can transform retail operations without relying on GPUs.
Thanks to a chatbot interface powered by open-source small language models and real-time data analytics, store associates can interact naturally through voice or text, receiving immediate information about product availability from Chooch's inventory system or crowd density from WaitTime's analytics platform. The assistant seamlessly translates these inquiries into actionable insights, helping staff make informed decisions that enhance customer experience while optimizing store operations, all powered by CPU processing.
The Edge IQ Retail Assistant represents a fundamental shift in AI deployment strategy for retail environments. While cloud-based AI services dominated early generative AI implementations, this solution demonstrates why running optimized language models directly on CPU servers at the edge delivers superior results for retail operations.
When a store associate inquires about current customer traffic, the assistant queries WaitTime's API, interpreting the crowd analytics data coming from on-premise cameras to provide meaningful insights about congestion points, checkout wait times, and optimal staffing distribution. This real-time information enables managers to direct employees where they're most needed, thereby enhancing both operational efficiency and customer satisfaction.
Similarly, inventory queries trigger connections to Chooch's Vision AI platform, which continuously monitors store shelves through computer vision. The assistant translates Chooch's detailed inventory data into actionable insights, informing staff about current stock levels, identifying low-stock items, and helping prevent potential stockouts before they impact customers.
By presenting this information conversationally, the assistant makes sophisticated inventory intelligence accessible to every employee, regardless of technical expertise, all processed locally on the CPU without requiring GPU acceleration.
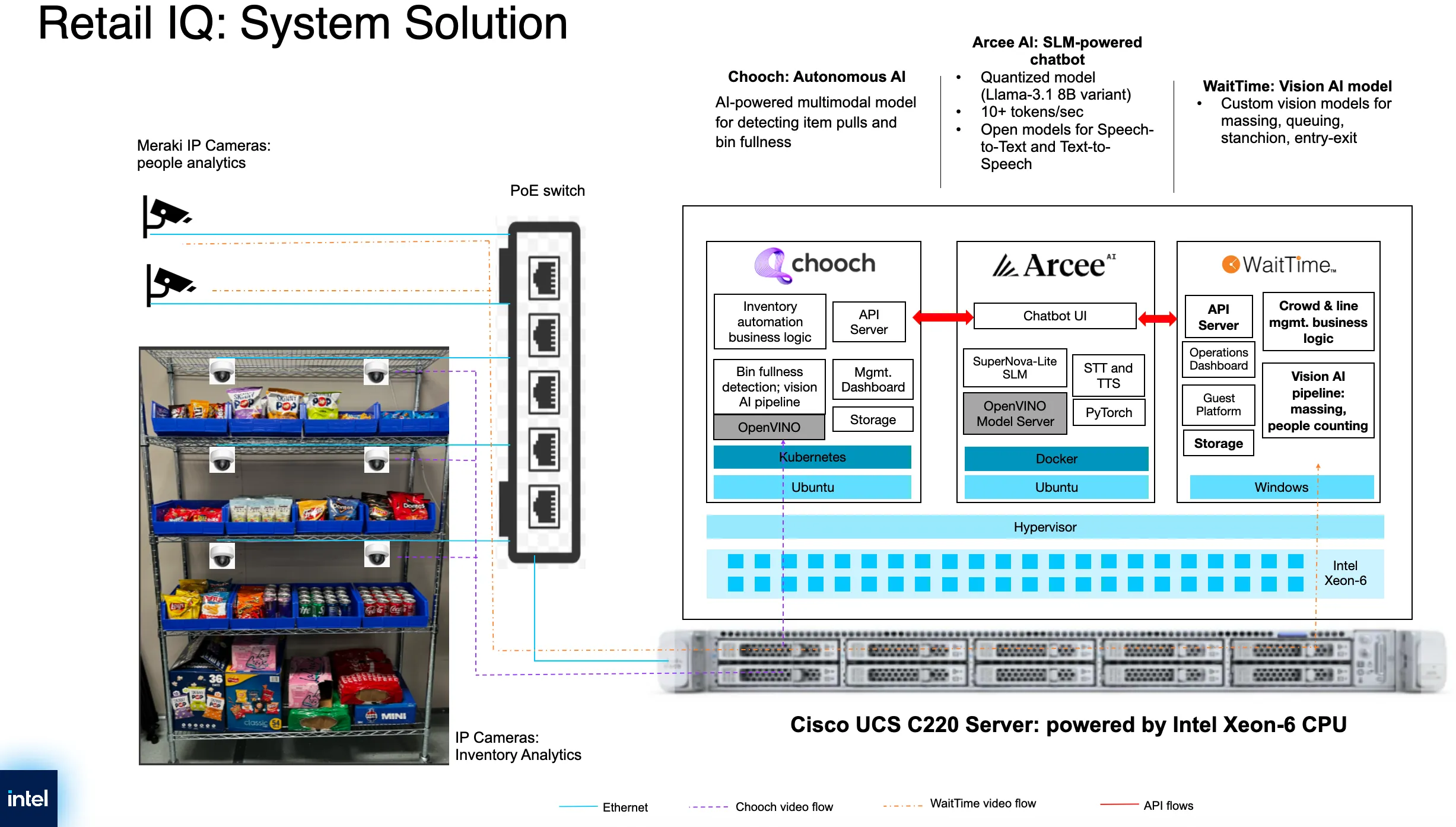
The Edge IQ Retail Assistant demonstrates the impressive capabilities of modern CPU-based AI inference. At its core, the application runs three sophisticated small language models entirely on Intel Xeon processors —no GPUs are present in the system architecture. This CPU-only approach highlights the significant progress in AI optimization and the remarkable capabilities of modern server processors for AI workloads.
Last but not least, we built the user interface with Hugging Face Gradio and containerized the entire solution with Docker for easy deployment and management.
The secret behind the Edge IQ Retail Assistant's impressive CPU-only performance lies in Intel's OpenVINO toolkit. This powerful optimization framework transforms resource-intensive models into highly efficient versions specifically tailored for execution on Intel Xeon 6 processors, applying numerous optimizations in the process.
Through model quantization, OpenVINO reduces SuperNova Lite's precision from 32-bit to just 4-bit representations, dramatically decreasing memory requirements while maintaining accuracy. Layer fusion combines multiple operations into a single optimized kernel, minimizing memory transfers and accelerating execution. Hardware-aware optimization automatically maps neural network operations to the most efficient instruction sets available on Intel Xeon processors, while memory layout transformations restructure tensors for optimal CPU execution.
The toolkit specifically targets Intel's specialized CPU instruction sets found in Intel Xeon processors. Advanced Vector Extensions (AVX-512) provide Single Instruction, Multiple Data capabilities that significantly accelerate the matrix operations underpinning neural networks. The newer Advanced Matrix Extensions (AMX) instruction set delivers remarkable performance for the matrix multiply-accumulate operations that dominate language model inference.
Our quantized SuperNova-Lite model runs on the OpenVINO Model Server, which provides dynamic batching of incoming requests, automatic model management, OpenAI API compatibility, and efficient parallel execution across available CPU cores.
The convergence of modern CPU architectures and robust server platforms marks a new era in retail operations. By harnessing the power of AI at the edge, retailers can achieve:
As the retail landscape continues to evolve, embracing edge AI solutions like the Edge IQ Retail Assistant will be crucial in staying competitive and meeting customer expectations.
If you’d like to know more about Arcee AI and our solutions, please visit us at www.arcee.ai or book a demo. We also recommend following us on LinkedIn or X to stay in touch with the latest news on small language models.
Technical resources

.webp)