Product
Discover Auto Reasoning, Arcee Conductor’s new feature that intelligently routes complex prompts to the best reasoning model. Learn how Maestro excels at multi-step problem solving and why advanced reasoning is critical for modern businesses.


Maestro is a compact model (just 32B) that performs strongly across math, coding, and open-domain reasoning–while keeping costs low. We trained it by reinforcing Qwen-2.5-32B with a critic-free algorithm called Group-Relative Policy Optimisation (GRPO). Before policy training started, the model was jump-started with logit-wise distillation from DeepSeek-R1, and its instruction set is continuously upgraded by an in-house evolution framework (EvolKit 2) that uses our Arcee SLM Virtuoso-Large as the “evolver” and DeepSeek-R1 as the provisional answerer.
Auto reasoning is fully accessible via direct API integration, making it easy to enhance your existing workflows, from security assessments to supplier selection. Whether you're tackling simple or complex reasoning tasks, our specialized models deliver dependable results without interrupting your operations.
Last week, we introduced our latest feature in Arcee Conductor: Auto Tools, which routes your tool-calling prompts to a selection of models that specialize in tool calling / function calling. Today, we’re introducing a similar feature for your prompts that involve complex reasoning: Auto Reasoning.
In this article, we explain why we built a mode focused on routing your reasoning prompts, how our reasoning model Maestro stands out in everyday reasoning tasks, and why an AI model's ability to tackle complex, multi-step problems is becoming essential for businesses today.
While standard language models excel at straightforward question-and-answer tasks, advanced AI systems with enhanced reasoning abilities can tackle complex scenarios, draw logical conclusions, and make informed decisions.This advanced level of understanding empowers organizations to tackle nuanced tasks such as risk assessment, strategic planning, and customer service automation with greater confidence and precision.
By investing in AI models that are specially trained in reasoning, businesses gain a powerful tool to navigate ambiguity, adapt to evolving challenges, and ultimately deliver more reliable and intelligent solutions to their customers.
Until now, the intelligent model routing feature of Arcee Conductor sent all prompts to the ideal model for performance and cost, choosing from a suite of small language models (SLMs) and large language models (LLMs). But with the new Auto Reasoning mode, you can ensure that your reasoning prompt is routed only to one of these models that’s specially-trained in reasoning:

To get started, in the Conductor UI just simply click the dropdown and switch from “Auto” mode, to “Auto Reasoning”mode. It’s as simple as that. (If you’re accessing Conductor via the Conductor API, just change the model name to "auto-reasoning”).
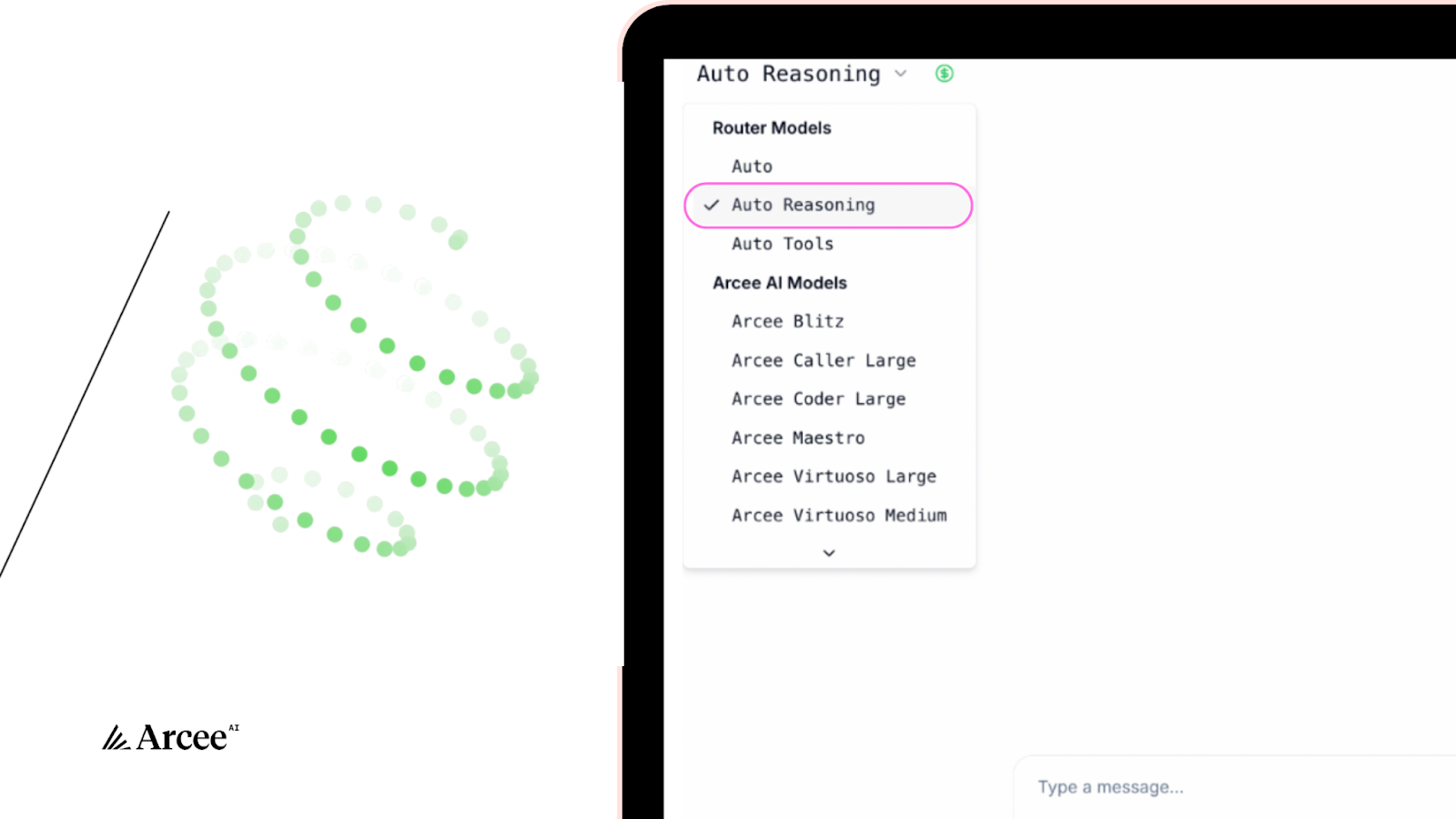
When you’re working in Auto Reasoning mode, your prompts that require the highest level of reasoning will be sent to the most appropriate LLM, and most of your less complex reasoning prompts will be routed to Arcee’s SLM, Maestro to help you balance cost and performance effectively.
{{tips}}
Not all reasoning prompts require the full power of the premium reasoning LLMs. Here are some examples of lower-complexity reasoning prompts that Conductor sends to Maestro, reducing your overall LLM usage and spend.
In the following examples, we compare Maestro with DeepSeek R1 on tasks that auto-reasoning mode would typically route to Maestro. DeepSeek R1, with its Mixture-of-Experts (MoE) architecture, is built to route inputs to specialized sub-networks for better efficiency and scalability. Now let’s see how Maestro proves it’s the best of the best when it comes to efficiency.
Prompt:
Audience: Customers who haven’t opened an email in 60 days.
Options:
"We miss you—come back?"
"Limited-time offer: 80% OFF!!!"
"Your account’s still here when you need it."
Task: Pick the best subject line number based on the audience.
Prompt Classification by auto-reasoning:
Text Generation Task, Business/Industrial domain; Complexity (1/10).
Results:
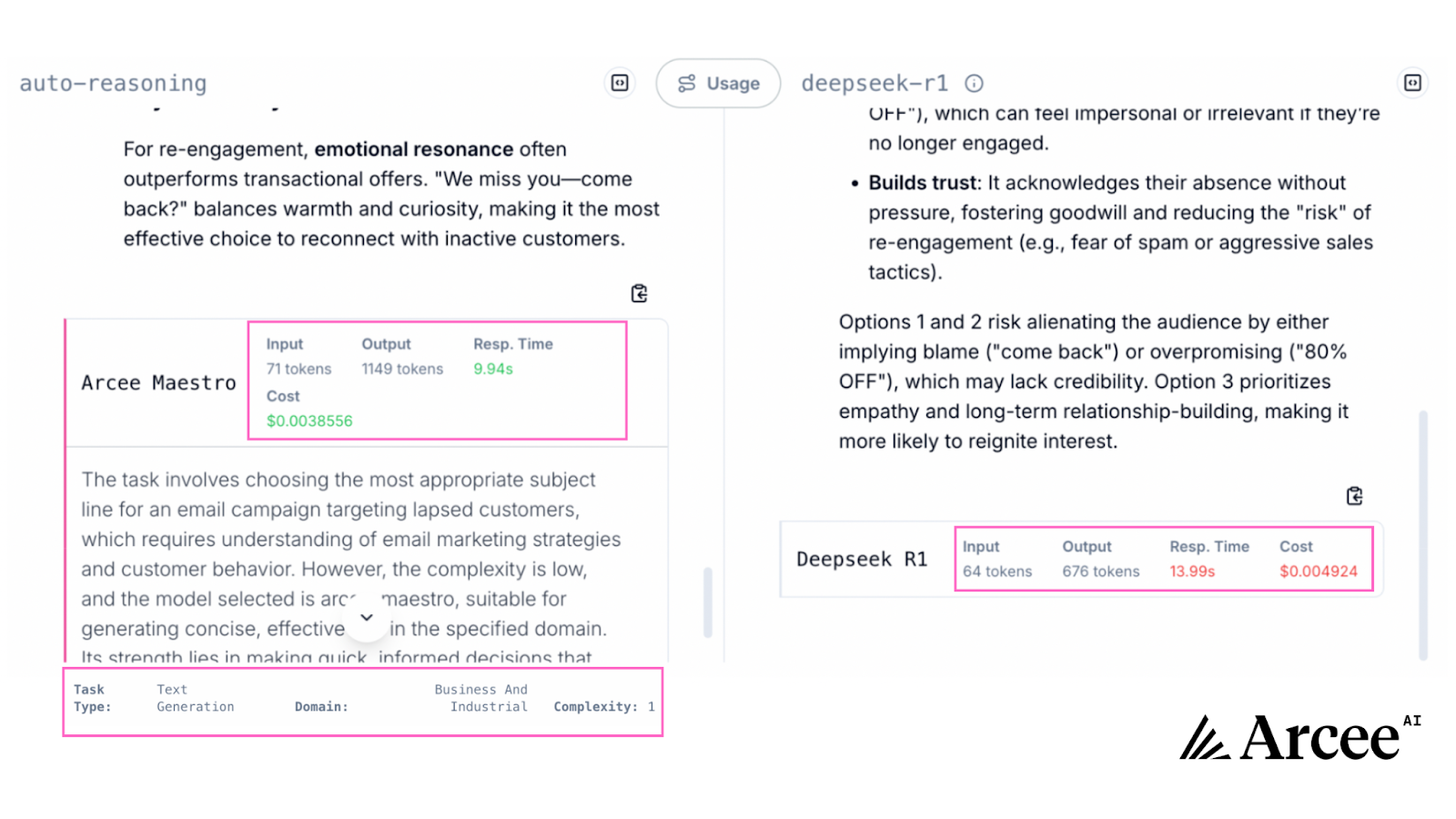
In this low-complexity email marketing task, both models offered strong approaches with different reasoning:
Which one resonates more with you? You decide. In the world of reasoning, there’s rarely a clear-cut answer; both sides present valid, well-supported perspectives, showing how different conclusions can still be equally sound.
Shifting from quality to efficiency, the raw performance data shows Maestro's clear edge for this type of prompt. It delivered 21.7% cost savings ($0.0038556 vs $0.004924) while generating more comprehensive insights (1149 output tokens vs. Deepseek's 676 output tokens).
For companies sending thousands of re-engagement emails daily, Maestro's approach delivers substantial operational savings while potentially improving open rates by 15-20%, enhancing both efficiency and performance.
Prompt:
Preference Hierarchy: Quality > Speed > Price
A. AlphaCo – excellent quality, average speed, high price
B. BetaLtd – good quality, fast, very high price
C. GammaInc – acceptable quality, slow, low price
Task: Which supplier best fits the hierarchy?
Prompt Classification by auto-reasoning:
Classification task, Business/Industrial domain; Complexity (1/10)
Results
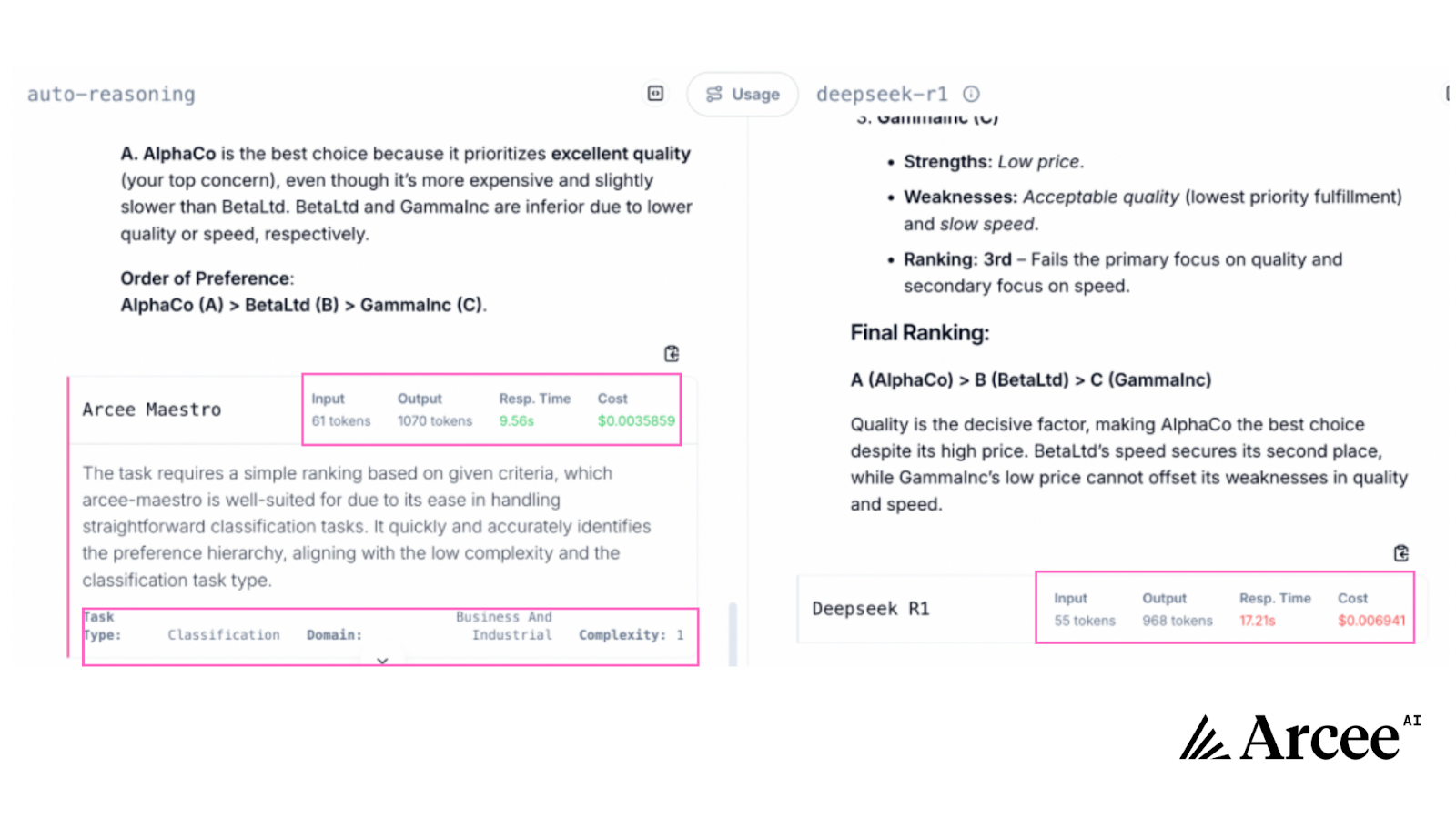
In this supplier evaluation scenario, both models applied similar weighted evaluation approaches and concluded that AlphaCo represents the best choice despite higher costs, recognizing that superior quality outweighs price considerations for this particular business need.
While both delivered similar results with strong performance and quality, Maestro's ability to deliver slightly more comprehensive output (1070 tokens vs 968) at nearly half the cost ($0.0035859 vs. $0.006941) and 44.45% faster (9.56s vs. 17.21s), speaks volumes about its efficiency advantage for similar everyday classification tasks.
For procurement teams making hundreds of similar evaluations monthly, Maestro's performance advantage translates to significant time and cost savings without sacrificing analytical quality.
Prompt:
Email Snippet:
"Dear User, your invoice is attached. Please sign in with the link below to view."
Clues:
Sender domain is invoices-secure.com (not your usual vendor)
Link points to a URL shortening service
Spelling and grammar look fine
Task: Is this email likely phishing?
Prompt Classification by auto-reasoning:
QA task type, complexity 1/10, internet domain
Results:
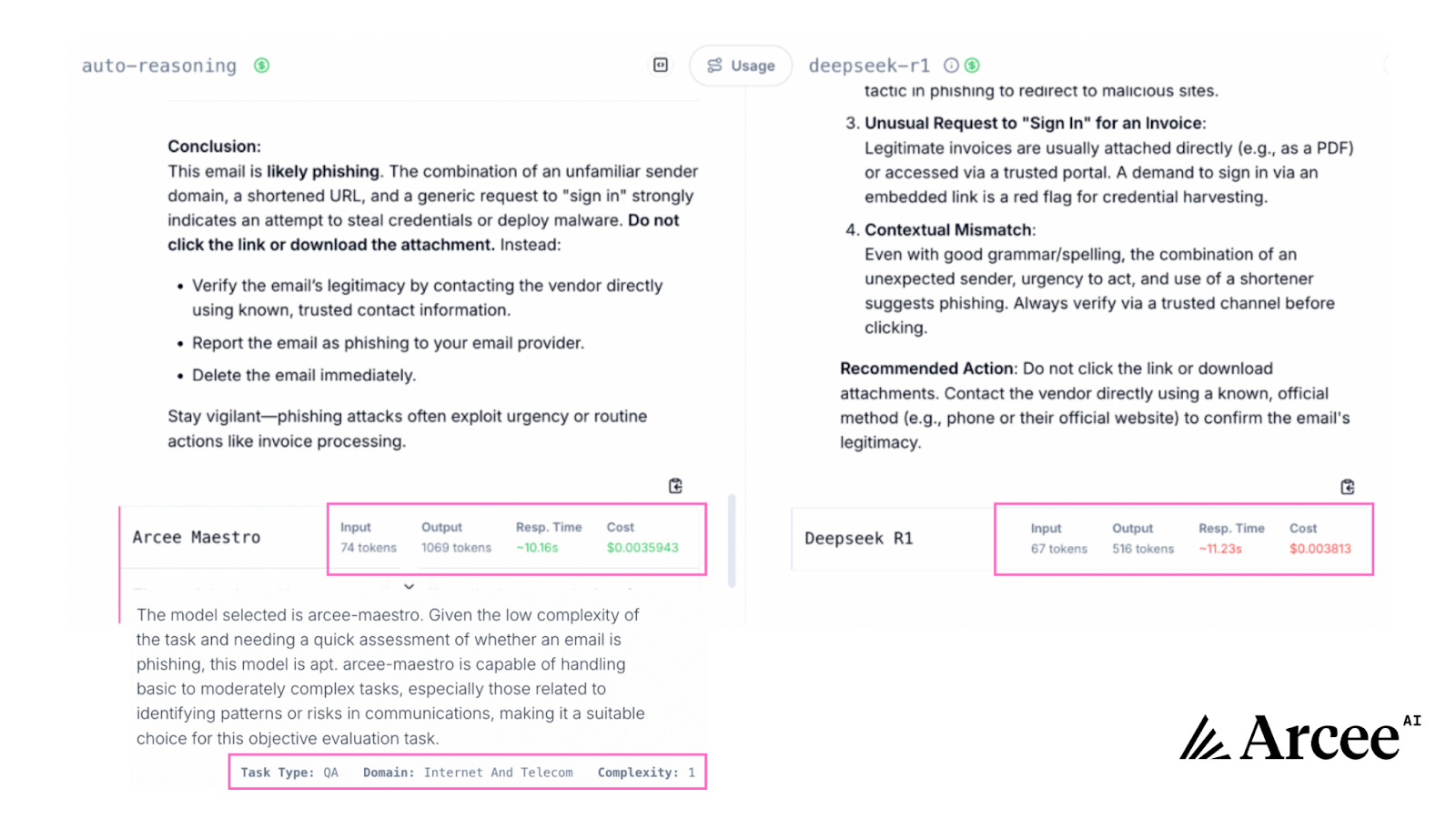
For this relatively straightforward phishing detection task, both models correctly identified the email as phishing. However, Maestro excelled by delivering more detailed and actionable recommendations (verify legitimacy, report the email, delete it), responding faster (10.16s vs. 11.23s), and costing 5.74% less ($0.0035943 vs $0.003813) while providing nearly twice the analytical depth (1069 tokens vs. 516 output tokens from DeepSeek-R1).
When scaled across enterprise environments processing thousands of suspicious emails daily, these performance differentials translate to significant operational advantages. Security teams can analyze more threats with greater speed, accuracy, and lower cost; And in environments where analysts are overwhelmed by alerts, Maestro’s clearer, actionable responses help cut through the noise and focus attention on real threats.
Overall, for businesses handling relatively low-complexity, routine decisions that still need thoughtful analysis, Auto Reasoning mode directs those prompts to Maestro, offering high-quality reasoning performance without the premium cost. As demonstrated in our email subject line selection and supplier preference examples, Maestro consistently provides comparable or superior analytical quality while offering significant advantages in both cost and speed.
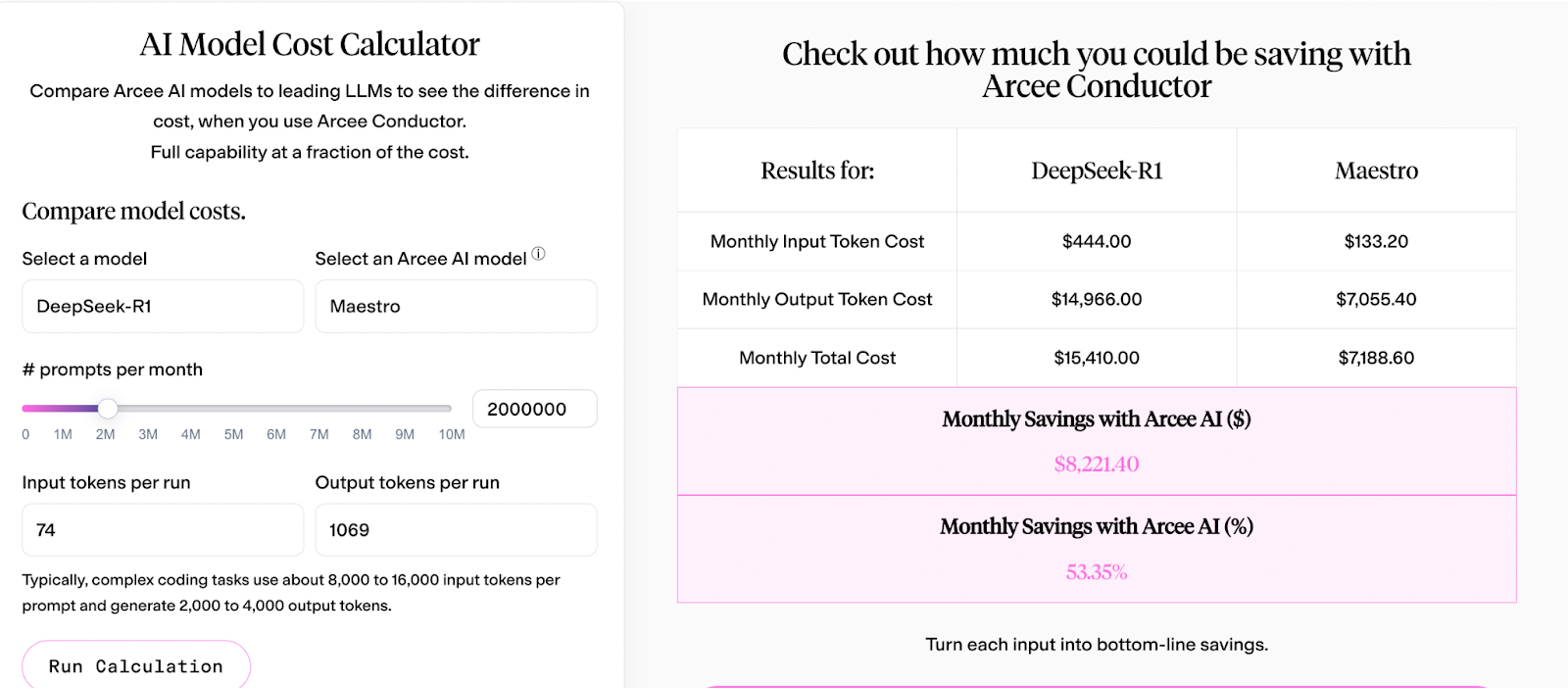
To understand Maestro's direct bottom-line impact, consider the numbers: Maestro runs at just $3.30 per million output tokens compared to DeepSeek R1's $7.00. For a team processing 2 million prompts monthly with similar characteristics to our phishing detection example (74 input tokens, 1069 output tokens), using Maestro could save approximately $8,221.40 per month. For a more personalized calculation, simply input your specific usage patterns into our AI model calculator to see your potential monthly savings.
{{tips2}}
Curious how businesses are using reasoning prompts in their day-to-day use cases? Here are some examples showing that smart use of reasoning AI models can offload many research, analysis, and evaluation tasks–saving your teams many hours of their valuable time:
By leveraging AI models trained in reasoning, companies can enhance their decision-making processes, improve operational efficiency, and drive innovation. These models not only analyze vast amounts of data at unprecedented speeds but also provide insights that are contextual and nuanced, allowing businesses to make more informed and strategic choices. Arcee Conductor’s Auto Reasoning mode is the perfect opportunity to incorporate reasoning AI models into your workflows, since it gives you access to multiple models, and ensures that you’re working with the best model for each reasoning prompt, always, of course, at the best price.
Sign up today for Arcee Conductor and get a $20 credit: https://conductor.arcee.ai/

Companies are becoming increasingly aware of the potential business value of open source large language models, which are quickly approaching the performance of their closed source counterparts.
Built for performance, compliance, and affordability.
.avif)
Arcee AI and Intel Gaudi2 make for a powerful combination when it comes to advancing financial insights via LLMs. Learn how the Arcee AI team used Intel's Habana Gaudi2 technology to train two advanced models with 10 billion tokens of financial data, leading to nuanced insights for analysts, investors, and other stakeholders.
Subscribe to our newsletter

.svg)



