From 4k to 64k context through aggressive experimentation, model merging, distillation, and a concerning amount of soup.
The other day Arcee finally announced the first of our from-scratch foundation models, AFM-4.5B. Learning to train a foundation model is a long and arduous journey, and there are many lessons and learnings that we will be sharing in the full tech report in the coming weeks. In the meantime, I wanted to pull back the curtain on one particular part of the training process: extending the context length.
We extended AFM-4.5B from 4k to 64k context through aggressive experimentation, model merging, distillation, and a concerning amount of soup. This post will be a pretty unflattering look at the raw meat of the experimental process and the various approaches we tried, eventually arriving at a final model that performs well on both short and long context tasks. Bon appétit.
Disclaimer: AFM-4.5B was recently introduced as a preview, with a full open-weight release (under a CC-BY-NC license) planned for early July. The evaluations presented here are based on our first checkpoint, captured immediately after the completion of our initial mid-training phase on June 3rd. The model continues to undergo additional training, including further pretraining, instruction tuning, and reinforcement learning. As a result, the benchmarks shared in this post reflect only these experiments and should be considered preliminary. Final benchmark results for the official release may differ as the model continues to improve.
Approaches to Long Context Training
Long-context training is a heavily researched topic, and there are many great publications that we stood on the shoulders of. Here's a little reading list of papers we found particularly useful:
Of these, SkyLadder stood out with a very interesting finding: given a fixed token budget, models trained on shorter context lengths pretty consistently outperform models trained on longer context lengths on standard benchmarks. Their solution is a training schedule that gradually increases the context length, with excellent results. Unfortunately, that's haaaaard to implement. I didn't want to modify torchtitan to handle variable context lengths. (Neither did anyone else on the team, so I don't feel too bad about it.) So we instead went for the more traditional approach of doing the initial training on a shorter context length and then extending it at the end. Bits and pieces from all of these papers made their way into the final model in one way or another, which I'll get to in a bit.
A Quick Note on Evaluation
Evaluating the quality of a context extended model is a bit tricky. There are great benchmarks for long context tasks now (like NVIDIA's RULER). But looking just at these can be a little misleading; context extension typically significantly degrades performance on short-context tasks. Long context is great, but what's the point if the model becomes substantially dumber in the process?
In this post I'm going to focus on the short-context performance -- specifically MMLU and Big Bench Hard, as they were highly correlated with our full eval suite -- as a proxy for the amount of degradation. (Rest assured long-context performance was also evaluated. I just don't want to format six thousand tables right now.)
Part 1: Dry Run (Or, Putting Down Tracks While the Train is Moving)
We kicked off the initial pretraining of AFM-4.5B with a 4096-token context length. This was the sweet spot for a tasty MFU while still being long enough to capture some interesting dependencies. This ran for around 5 trillion tokens, at which point we did a small annealing run (decaying the learning rate to zero) to get a preview of the fully trained model. We then continued the pretrain with an additional 1.5T tokens from our main corpus, before shifting gears for the final 10% of the run. Here we mixed in a more targeted distribution of math, code, and reasoning samples while maintaining a roughly 1:1 split with general web data to avoid catastrophic forgetting (the kids are calling it "midtraining" now I believe).
While the midtrain was running, I took the opportunity to start testing context extension strategies on the annealed model. This was a perfect dry run for the final model. The annealed checkpoint scored 65.4% on MMLU and 43.5% on BBH. Already great for its size and training stage. The goal: keep these numbers as high as possible while stretching the usable context window.
Step 1: Positional Embeddings
Pretty much all approaches to long-context training start with modifying the positional embeddings. There are many approaches here -- linear interpolation, ntk-aware, YaRN, LongRoPE, LongRoPE2, probably more that I'm forgetting. Each has production deployments and compelling arguments. Fortunately there's a handy heuristic we can use to pick one: which does DeepSeek use? And for DSv3 (and consequently R1), that's YaRN. So I went with YaRN, copying their parameters for a 4k->128k extension.
As you might expect, just applying YaRN made things look pretty gnarly. MMLU dropped to 55.0% and BBH to 36.0. This is typical. Training is always needed to recover performance after such a dramatic expansion, and this is where the fun begins.
Step 2: Training Experiments
Experiment 1: PoSE
PoSE is tantalizing because it promises to teach long context by training on short sequences, just with position IDs sampled from the target range. Being able to get to 128k without touching 128k-length data would be a huge win. The first experiment I ran was applying PoSE to the annealed model with an 8192 sequence length and a 128k target length.
Unfortunately, it didn't work so great. Post-PoSE, MMLU cratered to 48.8% (though BBH ticked up to 37.0%). That's pretty grim. It's still better than Llama2-7B, but that's not a high bar these days. Maybe with substantially more training or tweaking of parameters this could be a viable approach, or maybe the implementation used was off. But as it stood, it was a no-go.
Fortunately there's a handy tool that we can use to fix this, like any other problem in machine learning: model merging. A simple linear merge (using MergeKit) of the PoSE-extended model with the original annealed checkpoint brought MMLU back up to 59.1% and BBH to 40.0%. Still not great, but at least an improvement over the untrained YaRN model! This sort of improvement from merging became a recurring theme.
Experiment 2: ProLong
With PoSE results in hand, the next thing I wanted to try was the approach Princeton NLP used for their ProLong models. Following their paper, but with our own data as input, I trained a model with the same YaRN parameters at a true sequence length of 64k. This took much longer, but the results were far more promising. Post-ProLong, MMLU was 62.6% and BBH at 38.6%. Merging this back with the annealed checkpoint brought BBH up to 40.2%, but dropped MMLU to 61.8%. This was a bummer, because otherwise I could have truthfully said that merging improved every single experiment I ran. Alas. Still, ProLong became the clear front-runner.
Experiment 3: ProLonger
The initial ProLong run was for ~250M tokens. I ran it back with ~1.3B tokens to see how it scaled. This gave an MMLU of 62.7% and BBH of 40.4%. Merging with the annealed checkpoint left MMLU unchanged and pushed BBH to 41.5%. Pretty good! But getting back to full short-context performance was obviously going to take a lot more training, and that's boring. So I decided to try some other low-compute things before resorting to just throwing tokens at the problem.
Step 3: Make it Better Instantly and For Free
Soup Time 🧑🍳🍲 Wow Soup Now
You guessed it -- it's time for more model merging.
I had a bunch of checkpoints trained on the same task, all of varying quality. At this point, you are legally and morally obligated to make a soup. I threw the annealed checkpoint, the PoSE checkpoint, and the two ProLong checkpoints into a simple linear merge. This hit MMLU 63.6% and BBH 42.2%. Tasty.
Backing Off the Positional Embeddings
Since bumping positional embeddings caused the original performance drop, why not just... back them off a little bit? Adjusting the YaRN scale from 40 down to 20 brought MMLU to 64.0% with no BBH change. Neat! This was an interesting finding: it works really well to "overextend" a model by training it with a larger embedding range than your target, then backing off the scale post-training. This reproduces with individual training runs as well, not just the soups. I don't think I've seen this documented elsewhere but it seems like pretty much a free lunch.
Just Extending Less
Of course, 128k was never actually a specific target; it's just what we got from DeepSeek's YaRN parameters. Extending less will obviously give less degradation. So for comparison, I trained a ProLong model with parameters for a 32k sequence length. This was unsurprisingly pretty good, with MMLU of 63.0% and BBH of 41.0%.
Merge Even More
The soup hungers. Fresh checkpoints for the pot. Throwing the 32k ProLong model into the previous soup and backing off the positional embeddings to a 32k scale brought MMLU to 64.4% and BBH to 42.1%. This is solid. You could ship this.
But there were two problems:
32k context length is a little meh.
The midtrain had just finished, and this whole dry run was now out of date.
Part 2: The Real Deal
With lessons learned from our dry run, we turned to the real midtrained checkpoint. This set our new baseline: 66.0% on MMLU and 45.2% on BBH. A small but notable improvement. Time to enlongify.
Round 1: ProLong Once More
Given the success of the previous ProLong runs, I immediately ran another atop the midtrained checkpoint. This was another 1.3B tokens at a true sequence length of 64k and the YaRN parameters for 128k. This yielded an MMLU of 63.3% and BBH of 43.6%. A good start.
Round 2: Re-basing and Merging (Waste Not, Want Not)
No need to waste the previous work. I pulled a little trick and used a Task Arithmetic merge to "rebase" the 32k dry-run ubersoup onto the midtrained checkpoint. It's a simple formula: we create a "long context" task vector (dry_run_soup - annealed_checkpoint) and apply it to the new base. This can be thought of as transplanting the 'long-context skills' learned during the dry run onto our new, smarter base model. It's not perfect, but we have the perfect tool to smooth things out: more merging! Combining this rebased soup, the original midtrained checkpoint, and the new ProLong checkpoint yielded an MMLU of 64.6% and BBH of 43.1% plus solid 64k performance. This made a great intermediate "student" model for the next step.
Round 3: Short-Context Distillation
Here I cracked out another favorite tool in the Arcee toolkit. Using DistillKit I distilled the original short-context midtrained checkpoint (the 'teacher') into our long-context soup-of-soups (the 'student'). This is incredibly effective at recovering short-context performance. In less than two hours on an 8xH100 node, MMLU shot up to 65.0% and BBH hit 45.3%.
Round 4: ProLong Once More, Once More
Short-context performance was now stellar, but long-context eval past 32k was more hit-or-miss than I liked. We decided on a final target of 64k, so I ran one more full sequence length ProLong pass on top of the distilled checkpoint with the appropriate YaRN scaling. This gave excellent RULER results and maintained MMLU, but it bumped BBH down to 43.2%. I could not abide.
Round 5: Yes, it's Merging Again
To cap it all off, I did one final merge of the last ProLong checkpoint with the auto-distilled soup. I wanted to incorporate the minimal parameter changes necessary to get the long-context performance without hurting the short-context scores. This is a perfect use case for the Arcee Fusion method. Applying the fusion bumped BBH back up to 45.0% while maintaining performance on needle-in-a-haystack benchmarks at 100% up to 32k and 97% up to 64k. This was great, and I was finally ready to call it a day. End-to-end, including all experiments (and several omitted for brevity), this whole process took about 700 H100-hours of compute. Which still sounds like a heck of a lot to me but is not even a drop in the bucket compared to the rest of the pretraining budget. What a world we live in.
Of course we later ran continued pretraining from this 64k checkpoint, which brought further improvements and further model merging. But this is about the context extension process, and that's done.
Results
For your viewing convenience, here are the benchmark results mentioned in tabular form.
Dry Run Results
Experiment / Model
MMLU (%)
BBH (%)
Notes
Annealed Checkpoint (Baseline)
65.4
43.5
Our starting point.
↳ Just YaRN (no training)
55.0 (↓)
36.0 (↓)
Initial performance hit from RoPE scaling.
PoSE Training (8k seq)
48.8 (↓↓)
37.0 (↑)
Cratered MMLU. Not great.
↳ PoSE + Linear Merge
59.1 (↑)
40.0 (↑)
Merging saves the day.
ProLong Training (64k seq, 250M tok)
62.6
38.6
A much more promising approach.
↳ ProLong + Linear Merge
61.8 (↓)
40.2 (↑)
Merging helps, MMLU drops a bit.
ProLonger Training (64k seq, 1.3B tok)
62.7
40.4
More tokens, better scores.
↳ ProLonger + Linear Merge
62.7
41.5 (↑)
Improved BBH with no MMLU cost.
Initial Soup
63.6
42.2
(Annealed + PoSE + 2x ProLong)
↳ w/ Backed-off PE
64.0 (↑)
42.2
It's free MMLU.
ProLong 32k Training (32k seq, 1.3B tok)
63.3
41.0
A solid baseline for comparison.
Final Dry Run 32k Soup
64.4
42.1
(Initial Soup + 32k ProLong) with 32k PE
Real Deal Results
Experiment / Model
MMLU (%)
BBH (%)
Notes
Midtrained Checkpoint (Baseline)
66.0
45.2
Our new starting point.
↳ YaRN + ProLong Training (64k seq, 1.3B tok)
63.3 (↓)
43.6 (↓)
The expected drop on a new base.
Rebased Soup + ProLong Merge
64.6
43.1
Intermediate "student" model.
↳ Short-Context Distillation
65.0 (↑)
45.3 (↑)
Excellent recovery of short-context perf.
Final Full Context Training (64k seq)
65.0
43.2 (↓)
Great long-context, but hurt BBH.
Final Merge (Arcee Fusion)
65.0
45.0 (↑)
Best of both worlds. NiaH: 100%@32k, 97%@64k.
Validation at Scale: GLM-32B-Base
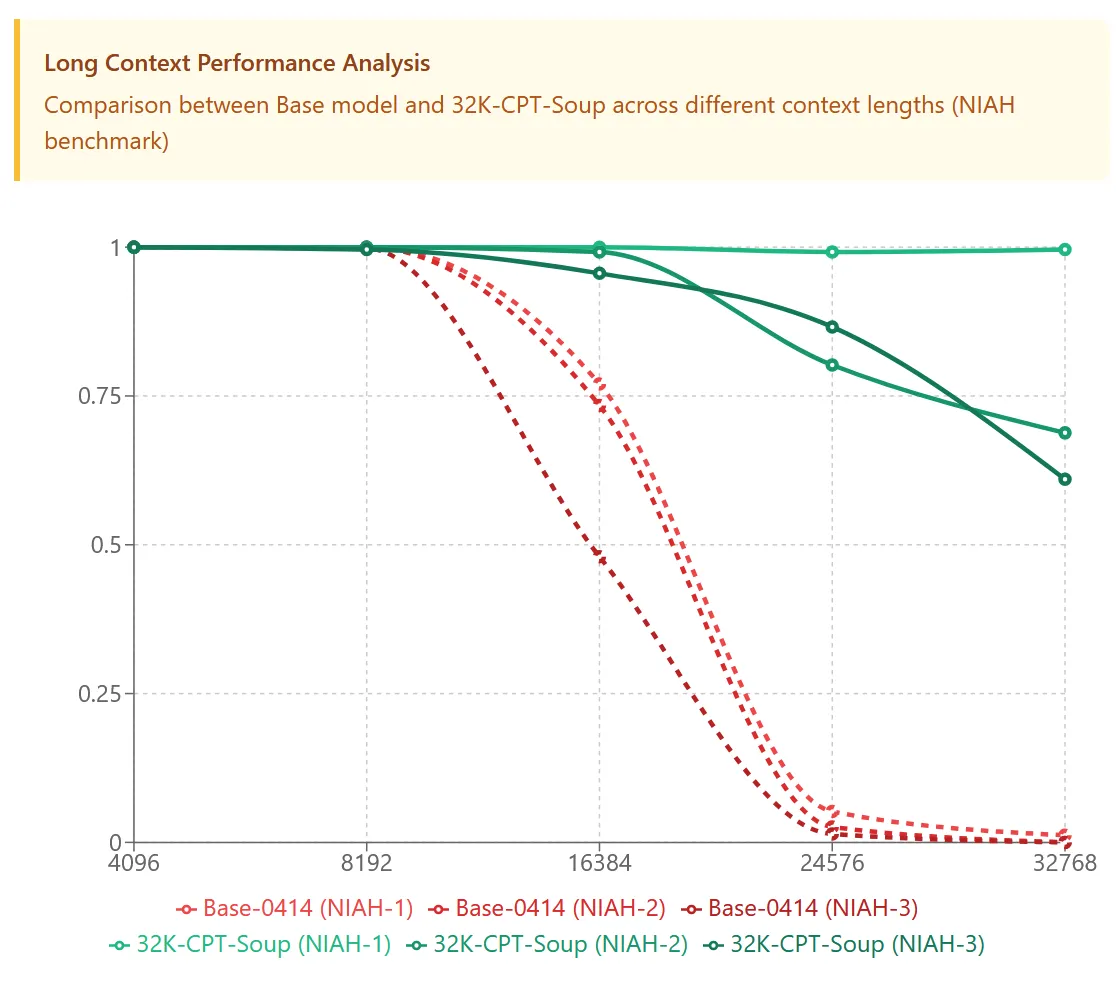
To further validate that this merging-centric approach can scale to larger models (looking to future AFM variants), I decided to test it on something bigger. Enter GLM 4 32B from Tsinghua University's THUDM group: a model with a 32k context window that shows strong performance up to 8192 tokens but rapidly degrades after that.
This seemed like a good test case. On a model 7x larger than AFM-4.5B, how well would these techniques hold up? As it turns out, quite well indeed.
Taking the same playbook from AFM, distillation from the short-context performance plus targeted long-context training and iterative merging, we managed to get ~5% overall improvements on standard base model benchmarks while dramatically improving 32k recall. The NIAH results speak for themselves: where the original model falls apart after 8k tokens, our enhanced version maintains solid performance all the way out to 32k.
We're releasing this improved version for anyone who wants a 32B GLM 4 base model with superior long-context capabilities. Consider it a proof point that these techniques aren't just for small models, they scale to larger parameter counts.
Conclusion
My brain is mostly soup now, but hopefully this is a useful overview of the process we used to extend AFM-4.5B to 64k context length. Some key takeaways:
When in Doubt, Merge: The world craves soup. Linear averaging is a ridiculously effective way to repair and combine experiments; don't underestimate it. Sprinkle advanced methods to taste. MergeKit has what you need.
Distillation is Your Friend: Distillation is a great way to recover short-context performance after long-context training. It can be done quickly and effectively with tools like DistillKit.
Overextend and Back Off: If you're extending positional embeddings and training, try overextending them and then backing off post-training. It's surprisingly effective and seems to be a free lunch.
Experimentation is Key: As in everything I write, I am unable to stress enough the importance of trying dumb things. If you try enough dumb things, eventually one of them will turn into a smart thing. Embrace the chaos.

.webp)