Optimizing Arcee Foundation Models on Intel CPUs

6 min read • Sep 30, 2025
Explore how to optimize small language models on Intel’s latest CPU, utilizing Arcee AI’s AFM-4.5B and Intel-optimized inference libraries.
The size of language models is often a barrier to running and scaling AI solutions where a business needs them. The pure size of the models leads to high inference costs and large hardware requirements. Small language models address this problem by enabling individuals and companies to run AI in the most cost-effective manner possible, anywhere. As we showcased in the blog "Is Running Language Models on CPU Really Viable?", SLMs and CPUs make a great combination for hosting language models at the edge, offering cost-effectiveness.
The combination of model size, capability, and hardware optimization showcases a major step toward making advanced models deployable on affordable, widely available hardware, paving the way for new opportunities in on-device intelligence beyond the cloud.
In this blog, we’ll showcase how to optimize Arcee’s first foundation model, AFM-4.5B, on Intel Xeon 6 with the Intel OpenVINO toolkit and the Hugging Face Optimum Intel library.
AFM-4.5B
We released AFM-4.5B in June 2025, and since then, customers have utilized it to power edge, in-environment, and agentic solutions. Outperforming all open-source models in its size range, as shown in the benchmarks below, AFM-4.5B presents itself as a top choice for edge and compute-constrained environments.
AFM-4.5B benchmarks against similar sized SLMs
Intel Xeon 6
Intel Xeon 6, codenamed Granite Rapids, is Intel’s latest server processor. The Xeon 6 processor features two CPU microarchitectures: Performance Cores (P-cores), optimized for compute-intensive, vector-based workloads such as AI and HPC, and Efficiency Cores (E-cores), optimized for task-parallel, scalar-based workloads like microservices. The P-core microarchitecture, combined with new dedicated instruction sets for AI inference, such as Advanced Matrix Extensions (AMX), results in improved efficiency and performance when running language models on the CPU.
Optimum Intel and OpenVINO
To fully leverage Intel’s processor enhancements, we’ll utilize Intel-optimized libraries.
OpenVINO is an open-source toolkit used to convert, optimize, and run inference on generative and traditional AI models on Intel hardware. In addition to CPU inference, OpenVINO also works well for GPUs and NPUs; however, this blog will focus on CPU. To host a model using OpenVINO, we’ll utilize the OpenVINO Model Server (OVMS).
OVMS abstracts the complexity of model inference and provides an OpenAI-compatible endpoint, making it easy to integrate into current AI projects. Below is a breakdown of what OVMS delivers under the hood.
OpenVINO Model Server (OVMS) technical architecture diagram
Optimum Intel is an open-source library from Hugging Face which simplifies the utilization of Intel libraries, including Intel Neural Compressor, Intel Extension for PyTorch, and OpenVINO. With Optimum Intel, we can quantize and convert a model to an OpenVINO usable format in a single CLI command, run inference on our model, and more.
Optimizing AFM-4.5B on Intel Xeon 6
In the demonstration below, we’re running AFM-4.5B on an r8i.8xlarge EC2 instance. Please note that we use the R-series instances because, at the time of release, they are the only AWS EC2 instances with Granite Rapids CPUs. The amount of RAM included with these instances is not required to run AFM-4.5B. If you are replicating this setup, we recommend checking to see if C-series (compute optimized) instances are available for a more cost-optimized configuration.
Here are the prerequisites to replicate the demonstration below:
- An Intel Xeon 6 server, e.g., an Amazon EC2 r8i.4xlarge or larger,
- Ubuntu 24,
- Docker (see https://docs.docker.com/engine/install/ubuntu/).
Once the server is running and you’ve connected to it, the first step is to install the required tool dependencies, i.e., git and virtualenv.
Next, let’s create a new virtual environment to ensure a clean OpenVINO setup.
You can now install OpenVINO. In fact, all it takes is a single command thanks to Hugging Face Optimum-Intel.
Before you can download and optimize AFM-4.5B, please check that you’ve accepted the terms of the model. If not, simply open the model page on the Hugging Face Hub and accept the terms of use.
You also need to programmatically log in to the Hugging Face Hub to allow Optimum-Intel to download the model. You will also need an authentication token.
Using the optimum-cli tool, you can now download and optimize AFM-4.5B. Let’s create 4-bit and 8-bit versions, and save each one in a local folder.
That’s all there is to it. Now, let’s generate text with the optimized models.
Testing AFM-4.5B with Optimum Intel
The simplest way to generate text is to use the high-level pipeline object in the Hugging Face transformers library, which fully supports Intel OpenVINO models.
Running this example should produce an output similar to the text below:
Arcee AI is an artificial intelligence research and engineering firm that specializes in developing and deploying advanced AI systems. The company focuses on creating high-performance, scalable, and customizable AI solutions for various industries.
This solution is extremely convenient if you’d like to embed the model directly in your API or application. Now, let’s see how we can deploy the model with a proper inference server, the Intel OpenVINO Model Server, also known as OVMS.
Deploying AFM-4.5B with the Intel OpenVINO Model Server
OVMS requires a configuration file that lists available models and their corresponding deployment options. We could write this file from scratch and point it at the models we just optimized.
Instead, let’s do everything in one simple step: convert AFM-4.5B and generate the OVMS configuration file.
First, let’s clone the OVMS repository and locate the appropriate export script.
The virtual environment that we created earlier contains all the appropriate dependencies, so no further installation is required. We can run the export script immediately.
It's time to review the OVMS configuration file.
Output:
This is the simplest possible file. Many options are available; please refer to the OVMS documentation for details.
Now, you can run OVMS and deploy the models. The inference endpoint will be available on port 8000.
In the startup log, you should see that the server has properly initialized the two variants of the model.
OVMS is running, and you can now invoke the models.
Invoke AFM-4.5B with curl
In another terminal, you can simply invoke either one of the deployed models with curl. OVMS is compatible with the OpenAI Completions API, as visible in the example below.
If you’d like to invoke the 4-bit model, simply replace afm_45b_ov_int8 with afm_45b_ov_int4 in the command above.
To conclude this demonstration, let’s invoke the model with the Python OpenAI client.
Invoke the model with the Python OpenAI client
Let’s include the OpenAI client.
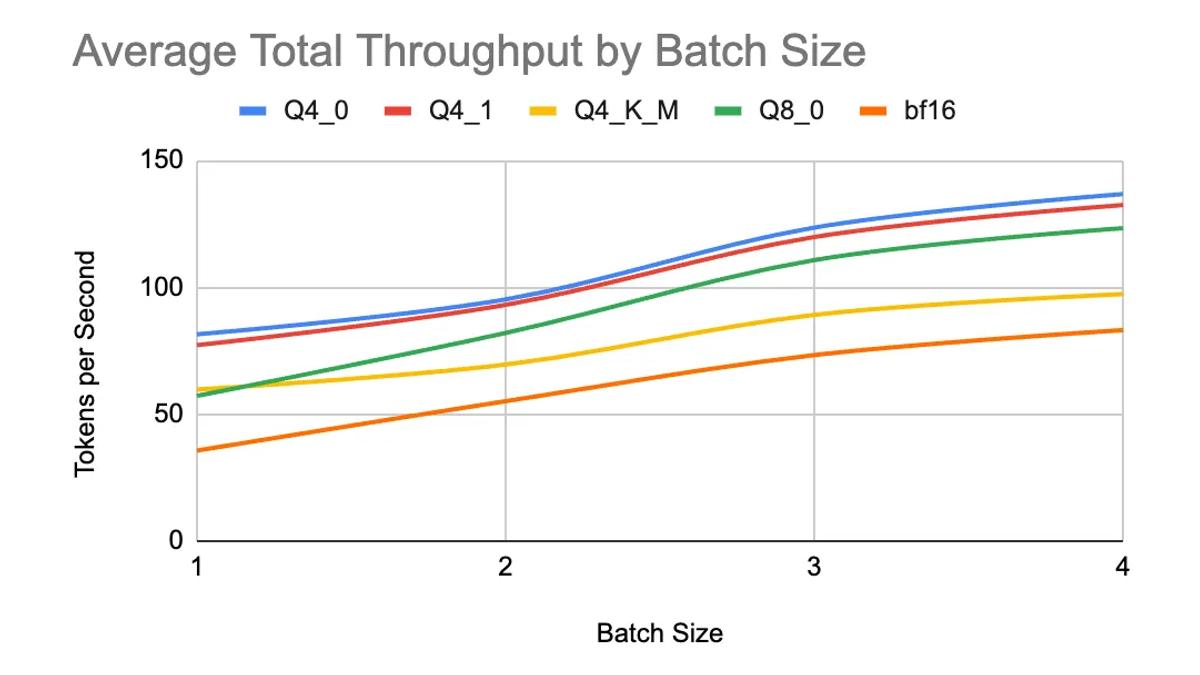
Here’s a simple example with streaming enabled, which will give us a sense of the generation speed we can achieve with AFM-4.5B on Intel Xeon 6.
Again, feel free to try the 4-bit model as well.
Once you’re done testing, you can simply shut down OVMS. If you launched an AWS instance (or any other cloud instance) for this demonstration, don’t forget to terminate it to avoid unnecessary charges!
Conclusion
Optimizing Arcee’s AFM-4.5B with Intel’s Xeon 6 processors, OpenVINO, and Optimum Intel demonstrates that running high-quality small language models on CPUs is not only viable but efficient and cost-effective. Whether embedded directly into applications via Optimum Intel or deployed at scale with the OpenVINO Model Server, AFM-4.5B delivers a powerful balance of accuracy, speed, and accessibility for edge and enterprise workloads.
As AI adoption continues to expand beyond large data centers, the combination of small language models and CPU-optimized toolchains will be key to democratizing access to generative AI—making it deployable anywhere, by anyone.
Resources
- https://aws.amazon.com/blogs/aws/best-performance-and-fastest-memory-with-the-new-amazon-ec2-r8i-and-r8i-flex-instances/
- https://www.intel.com/content/www/us/en/products/details/processors/xeon.html
- https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/overview.html
- https://github.com/openvinotoolkit/openvino.genai
- https://openvinotoolkit.github.io/openvino.genai/docs/getting-started/installation/
- https://openvinotoolkit.github.io/openvino.genai/docs/guides/model-preparation/convert-to-openvino