.webp)
News
•
April 1, 2026
Trinity-Large-Thinking: Scaling an Open Source Frontier Agent
Trinity-Large-Thinking is live. A frontier open reasoning model for complex, long-horizon agents and multi-turn tool calling released under Apache 2.0.

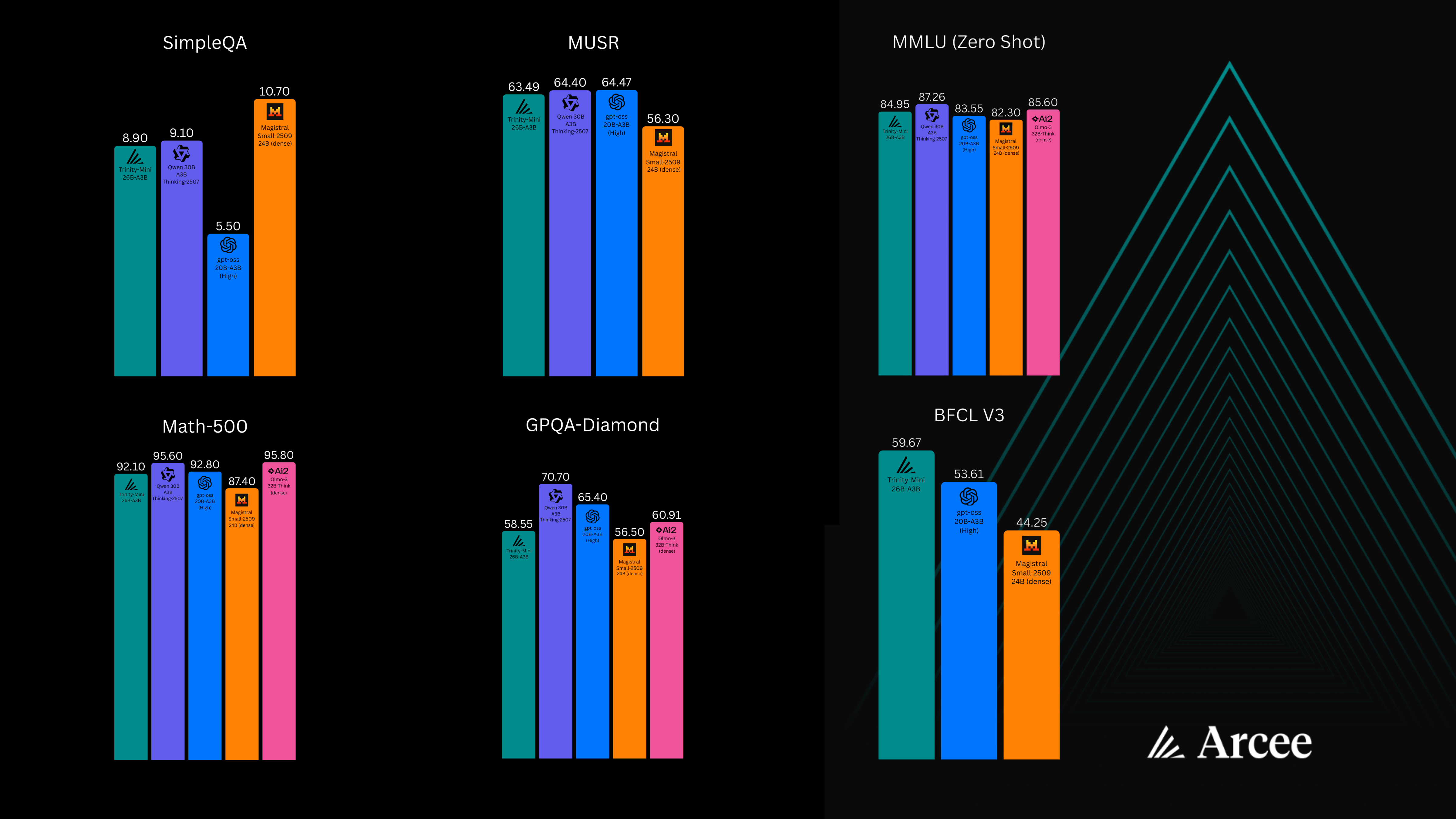
Arcee introduces Trinity Mini, a compact MoE model trained end-to-end in the U.S., offering open weights, strong reasoning, and full control for developers.
Over the last year, anyone who cares about open weight language models has been watching Chinese labs.
Qwen, DeepSeek and others now define a lot of what "state of the art open MoE" looks like. In the United States, most of the action has centered on polishing other people's checkpoints.
At Arcee AI we want to add something that has been missing in that picture: a serious open weight model family trained end to end in America, by an American company, with weights that businesses and developers can actually own.
That family is Trinity.
Trinity Nano and Trinity Mini are available now.
Trinity Large is currently training on 2048 B300 GPUs and will arrive in January 2026.
Trinity Mini is our fully post-trained reasoning model. Trinity Nano Preview is something different: a personality-forward chat model that pushes the limits of sparsity with only 800M non-embedding parameters active per token across 56 layers and 128 experts. It's charming, it's fun to talk to, and it may be unstable in edge cases. This is an experimental release, not a thinking model. Nano Preview is available to download from Hugging Face but won't be hosted on our API.
This is the story of why we decided to go all in on pretraining, how Nano and Mini came to life, and where Trinity is headed next.
For a while, our strategy looked like everyone else's. Take a strong open base, post train it hard, wire it into tools and RAG, and ship.
That approach carried us very far. You can get impressive behavior with a good base, careful data and an instruction stack that matches the product.
At the same time, a few pressures kept building:
We still use and appreciate great open-source models from others. We just came to the conclusion that if we want to offer truly long-lived, self-improving systems to customers, we also need to train our own foundations.
Our first step was AFM-4.5B, a dense 4.5B model trained on about 8 trillion curated tokens in partnership with DatologyAI.
AFM-4.5B was our "can we do this at all" experiment:
It worked. AFM-4.5B gave us a solid base of training and infrastructure practices, and showed us where to focus on capability improvements, especially around math and code.
Those lessons feed directly into Trinity.
Trinity is our open weight MoE family. We chose to leap directly toward the frontier and then worked backward from that goal, which meant designing Nano and Mini as the two form factors that could both serve real users today and teach us how to train something far larger.
Both are released under Apache 2.0. Download Nano Preview and Mini from Hugging Face. Mini is also available through our API and OpenRouter. Nano Preview is download-only.
Originally we thought of Nano and Mini strictly as training wheels for Trinity Large. The plan was to iron out our MoE recipe, then move on. In practice, the models proved stronger than expected and now serve different roles:
Building on our AFM naming convention, we refer to this Trinity architecture as afmoe, which integrates leading global architectural advances such as gated attention and Muon within a clean, US-controlled data pipeline. Here is what the stack looks like.
The attention mechanism combines several techniques that have proven effective at scale. We use grouped-query attention, mapping multiple query heads to each key-value head to reduce memory bandwidth during inference. Before computing scaled dot-product attention, we apply RMSNorm to the queries and keys (QK-norm), which stabilizes training.
We also use gated attention, specifically the G1 configuration from the Qwen paper. After SDPA, the output is elementwise-gated before the output projection: out_proj(sdpa_out * \\sigma(gate_proj(x))). This gives the model a learned ability to modulate attention outputs per-position.
Finally, we adopt a local/global attention pattern at a 3:1 ratio. Three local attention layers with RoPE are followed by one global attention layer without positional embeddings (NoPE). This pattern reduces compute on long sequences while preserving the model's ability to reason over distant context.
For layer normalization, we use a simplified version of depth-scaled sandwich norm. Each sublayer computes output = x + norm(module(norm(x))) . To enable stable training at depth, we initialize the gamma parameters of each norm layer to 1/sqrt(L) where L is the total layer count. We also apply a norm before the language modeling head.
Our MoE layers follow the DeepSeekMoE design: fine-grained experts plus a shared expert. Each MoE layer has 128 total routed experts, of which 8 are active per token, alongside 1 shared expert that is always active. The first two layers of the model are dense rather than sparse, providing a shared representational foundation before specialization begins, which we found improves training stability early.
For routing, we use sigmoid routing as introduced in DeepSeek-V3. Routing scores are computed with sigmoid followed by normalization rather than softmax. We also adopt the aux-loss-free load balancing scheme: an independently updated bias term determines routing decisions but is excluded from the weighting computation for each expert's contribution. This eliminates the need for auxiliary load-balancing losses that can distort the training objective.
We initialize all trainable parameters from a truncated normal distribution with standard deviation 0.5/sqrt(dim). During the forward pass, we multiply the embedding output by sqrt(dim).
We train with Muon, using the distributed implementation from Microsoft's Dion repository. To transfer learning rates across parameter shapes, we set adjusted_lr = lr * sqrt(max(1, fan_out / fan_in)), which we empirically observe enables optimal learning rate transfer when scaling. We sweep the Adam learning rate and Muon learning rate separately. The learning rate schedule we use is WSD (warmup-stable-decay). We apply no weight decay to embeddings.
Training runs on a modified version of TorchTitan in bf16 precision. Nano and Mini trained on 512 H200 GPUs using an HSDP parallelism setup with a global batch size of 8192 sequences at 4096 tokens each.
We only expanded the global attention layers during context extension, which allowed the model to learn extended sequence lengths very quickly. Trinity Nano was trained at 256k sequence length (inference at 128k), and Trinity Mini was trained at 128k sequence length.

Trinity Nano and Mini train on 10T tokens, organized into three phases with progressively higher quality and STEM concentration: 7T tokens in phase 1, 1.8T tokens in phase 2, and 1.2T tokens in phase 3. This curriculum allows the model to build broad coverage early and then sharpen on high-signal data. The mix reuses our curated AFM dataset and adds substantially more math and code.
Datology continued to be a key partner on the data side. On the compute and systems side we worked closely with Prime Intellect. They not only served the H100 clusters Datology used to generate synthetic data, they have been deeply involved in helping scale our training setup to the GPU footprint required for a fully frontier sized model, including the current 2048 B300 GPU configuration for Trinity Large.
MoE training at scale is messy. There is no polite way to say it. It is fucking hard. Here’s how we prepared for Trinity-Large:
The work is demanding, but it is also where most of the fun is. Every bug we chase and every learning curve we overcome feed directly into models that anyone can download and build upon.
Looking forward, we see a clear pattern.
As applications get more ambitious, the boundary between "model" and "product" keeps moving. Systems will:
Those systems will blur the distinction between pretraining data, synthetic data, post training tasks and live feedback. They will evolve continuously in the environments where they are deployed.
To do that responsibly and effectively, you need control of the weights and the training loop. You need to decide what kind of data the model sees, what objectives it optimizes, and how its capabilities change over time.
Our goal with Trinity is to provide that foundation for businesses, enterprises and developers who want ownership rather than a black box.
All of this leads to Trinity Large.
For most of this post we have talked about principles, data and architecture without naming the final size.
Trinity Large is a 420B parameter model with 13B active parameters per token.
Nano and Mini exist to make that possible, and to give the community strong open models to use right now while Large trains.
When Trinity Large ships, we will release a full technical report covering how we went from a 4.5B dense model to an open frontier MoE in just over six months.
If you care about open weight models, and you want an American MoE family that aims squarely at the frontier while staying fully permissive, we invite you to start working with Trinity today.
Break them. Push them. Tell us where they shine and, more importantly, where they fail. That feedback will shape Trinity Large and everything that follows.
We are building these models so that you can own them.
.webp)
.webp)